
Kaggle challenges us to learn data analysis and machine learning from the data the Titanic shipwreck, and try predict survival and get familiar with ML basics.
So, this material is intended to cover most of the techniques of data analysis and ML in Python, than to properly compete in Kaggle. That is why it following the natural flow of ML and contains many texts and links regarding the techniques, made your conference and references easy. as it can be extended over time.
In this way the material can be used for consultation and apply the methods to other similar classification cases, but for its application in the competition, or even to a real case, it will be necessary to make some choices and changes.
Competition Description:
The sinking of the RMS Titanic is one of the most infamous shipwrecks in history. On April 15, 1912, during her maiden voyage, the Titanic sank after colliding with an iceberg, killing 1502 out of 2224 passengers and crew. This sensational tragedy shocked the international community and led to better safety regulations for ships.
One of the reasons that the shipwreck led to such loss of life was that there were not enough lifeboats for the passengers and crew. Although there was some element of luck involved in surviving the sinking, some groups of people were more likely to survive than others, such as women, children, and the upper-class.
In this challenge, Kaggle ask you to complete the analysis of what sorts of people were likely to survive. In particular, they ask you to apply the tools of machine learning to predict which passengers survived the tragedy.

Table of Contents
- 1 Preparing environment and uploading data
- 2 Exploratory Data Analysis (EDA) & Feature Engineering
- 3 Select Features
- 4 Additional Feature Engineering: Feature transformation
- 5 Modeling – Hyper Parametrization
- 5.1 Simplify Get Results
- 5.2 Logistic Regression
- 5.3 SGDClassifier
- 5.4 Linear Support Vector Classification
- 5.5 Gaussian Process Classifier (GPC)
- 5.6 Random Forest Classifier
- 5.7 AdaBoost classifier
- 5.8 K-Nearest Neighbors
- 5.9 Multi-layer Perceptron classifier
- 5.10 Gradient Boosting for Classification
- 5.11 XGBoost (eXtreme Gradient Boosting)
- 6 Finalize The Model: Stacking the Models
- 7 Conclusion
Preparing environment and uploading data¶
You can download the this python notebook and data from my github repository. The data can download on Kaggle here.
Import Packages¶
import os
import warnings
warnings.simplefilter(action = 'ignore', category=FutureWarning)
warnings.filterwarnings('ignore')
def ignore_warn(*args, **kwargs):
pass
warnings.warn = ignore_warn #ignore annoying warning (from sklearn and seaborn)
import numpy as np
import pandas as pd
import pylab
import seaborn as sns
sns.set(style="ticks", color_codes=True, font_scale=1.5)
from matplotlib import pyplot as plt
from matplotlib.ticker import FormatStrFormatter
from matplotlib.colors import ListedColormap
%matplotlib inline
import mpl_toolkits
from mpl_toolkits.mplot3d import Axes3D
import model_evaluation_utils as meu
from scipy.stats import skew, norm, probplot, boxcox
from patsy import dmatrices
import statsmodels.api as sm
from statsmodels.stats.outliers_influence import variance_inflation_factor
from sklearn.feature_selection import f_classif, chi2, SelectKBest, SelectFromModel
from boruta import BorutaPy
from rfpimp import *
from sklearn.decomposition import PCA, KernelPCA
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.preprocessing import StandardScaler, PolynomialFeatures, MinMaxScaler
from sklearn.pipeline import Pipeline, make_pipeline
from sklearn.model_selection import GridSearchCV, cross_val_score, KFold, cross_val_predict, train_test_split
from sklearn.metrics import roc_auc_score, roc_curve, auc, accuracy_score
from sklearn.linear_model import LogisticRegression, SGDClassifier
from sklearn.svm import SVC, LinearSVC
from sklearn.gaussian_process import GaussianProcessClassifier
from sklearn.gaussian_process.kernels import RBF
from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, ExtraTreesClassifier
from sklearn.ensemble.gradient_boosting import GradientBoostingClassifier
from sklearn.neural_network import MLPClassifier
from sklearn.neighbors import KNeighborsClassifier
import xgboost as xgb
from xgboost import XGBClassifier
from xgboost import plot_importance
#from sklearn.base import BaseEstimator, TransformerMixin, clone, ClassifierMixin
from sklearn.ensemble import VotingClassifier
from itertools import combinations
Load Datasets¶
I start with load the datasets with pandas, and concatenate them.
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
Test_ID = test.PassengerId
test.insert(loc=1, column='Survived', value=-1)
data = pd.concat([train, test], ignore_index=True)
Exploratory Data Analysis (EDA) & Feature Engineering¶
Take a First Look of our Data:¶
I created the function below to simplify the analysis of general characteristics of the data. Inspired on the str function of R, this function returns the types, counts, distinct, count nulls, missing ratio and uniques values of each field/feature.
If the study involve some supervised learning, this function can return the study of the correlation, for this we just need provide the independent variable to the pred parameter.
Also, if your return is stored in a variable you can evaluate it in more detail, specific of a field, or sort them from different perspectives
def rstr(df, pred=None):
obs = df.shape[0]
types = df.dtypes
counts = df.apply(lambda x: x.count())
uniques = df.apply(lambda x: [x.unique()])
nulls = df.apply(lambda x: x.isnull().sum())
distincts = df.apply(lambda x: x.unique().shape[0])
missing_ration = (df.isnull().sum()/ obs) * 100
skewness = df.skew()
kurtosis = df.kurt()
print('Data shape:', df.shape)
if pred is None:
cols = ['types', 'counts', 'distincts', 'nulls', 'missing ration', 'uniques', 'skewness', 'kurtosis']
str = pd.concat([types, counts, distincts, nulls, missing_ration, uniques, skewness, kurtosis], axis = 1)
else:
corr = df.corr()[pred]
str = pd.concat([types, counts, distincts, nulls, missing_ration, uniques, skewness, kurtosis, corr], axis = 1, sort=False)
corr_col = 'corr ' + pred
cols = ['types', 'counts', 'distincts', 'nulls', 'missing_ration', 'uniques', 'skewness', 'kurtosis', corr_col ]
str.columns = cols
dtypes = str.types.value_counts()
print('___________________________\nData types:\n',str.types.value_counts())
print('___________________________')
return str
details = rstr(data.loc[: ,'Survived' : 'Embarked'], 'Survived')
details.sort_values(by='corr Survived', ascending=False)
Data Dictionary
- Survived: 0 = No, 1 = Yes. I use -1 to can separate test data from training data.
- Fare: The passenger fare
- Parch: # of parents / children aboard the Titanic
- SibSp: # of siblings / spouses aboard the Titanic
- Age: Age in years
- Pclass: Ticket class 1 = 1st, 2 = 2nd, 3 = 3rd
- Name: Name of the passenger
- Sex: Sex of the passenger male and female
- Ticket: Ticket number
- Cabin: Cabin number
- Embarked: Port of Embarkation C = Cherbourg, Q = Queenstown, S = Southampton
The points of attention we have here are:
- Fare: Kaggle affirm that is the passenger fare, but with some data inspection in group of Tickets we discover that is the total amount fare paid for a ticket, and the existence of tickets for a group of passengers.
- Parch: The dataset defines family relations in this way…
- Parent = mother, father
- Child = daughter, son, stepdaughter, stepson
- Some children traveled only with a nanny, therefore parch=0 for them.
- SibSP: The dataset defines family relations in this way…
- Sibling = brother, sister, stepbrother, stepsister
- Spouse = husband, wife (mistresses and fiancés were ignored)
- Age: Have 20% of nulls, so we have to find a more efficient way of filling them out with just a single value, like the median for example.
- Name: is a categorical data with a high distinct values as expect. The first reaction is drop this column, but we can use it to training different data engineering techniques, to see if we can get some valuable data. Besides that, notice that has two pairs of passengers with the same name?
- Ticket Other categorical data, but in this case it have only 71% of distinct values and don’t have nulls. So, it is possible that some passenger voyage in groups and use the same ticket. Beyond that, we can check to if we can extract other interesting thought form it.
- Cabin: the high number of distinct values (187) and nulls (77.5%).
This is a categorical data of which I use to train different techniques to extract some information of value and null input, but with given the high rate of null the recommended would be to simplify the filling or even to exclude this attribute.
First see of some stats of Numeric Data¶
So, for the main statistics of our numeric data describe the function (like the summary of R)
print('Data is not balanced! Has {:2.2%} survives'.format(train.Survived.describe()[1]))
display(data.loc[: ,'Pclass' : 'Embarked'].describe().transpose())
print('Survived: [1] Survived; [0] Died; [-1] Test Data set:\n',data.Survived.value_counts())
def charts(feature, df):
print('\n ____________________________ Plots of', feature, 'per Survived and Dead: ____________________________')
# Pie of all Data
fig = plt.figure(figsize=(20,5))
f1 = fig.add_subplot(131)
cnt = df[feature].value_counts()
g = plt.pie(cnt, labels=cnt.index, autopct='%1.1f%%', shadow=True, startangle=90)
# Count Plot By Survived and Dead
f = fig.add_subplot(132)
g = sns.countplot(x=feature, hue='Survived', hue_order=[1,0], data=df, ax=f)
# Percent stacked Plot
survived = df[df['Survived']==1][feature].value_counts()
dead = df[df['Survived']==0][feature].value_counts()
df2 = pd.DataFrame([survived,dead])
df2.index = ['Survived','Dead']
df2 = df2.T
df2 = df2.fillna(0)
df2['Total'] = df2.Survived + df2.Dead
df2.Survived = df2.Survived/df2.Total
df2.Dead = df2.Dead/df2.Total
df2.drop(['Total'], axis=1, inplace=True)
f = fig.add_subplot(133)
df2.plot(kind='bar', stacked=True, ax=f)
del df2, g, f, cnt, dead, fig
Ticket¶

Since Ticket is a transaction and categorical data, the first insight is drop this feature, but we may note that it has some hidden value information. At first look, safe few cases, we could affirms that:
- families and group of persons that traveled together bought the same ticket.
- People with alphanumerics Tickets has some special treatment (crew family, employees, VIP, free tickets, etc.)
So, we start by a new feature creation to quantify the number of passengers by ticket, and join this
quantity to each passenger with the same ticket.
same_ticket = data.Ticket.value_counts()
data['qtd_same_ticket'] = data.Ticket.apply(lambda x: same_ticket[x])
del same_ticket
charts('qtd_same_ticket', data[data.Survived>=0])
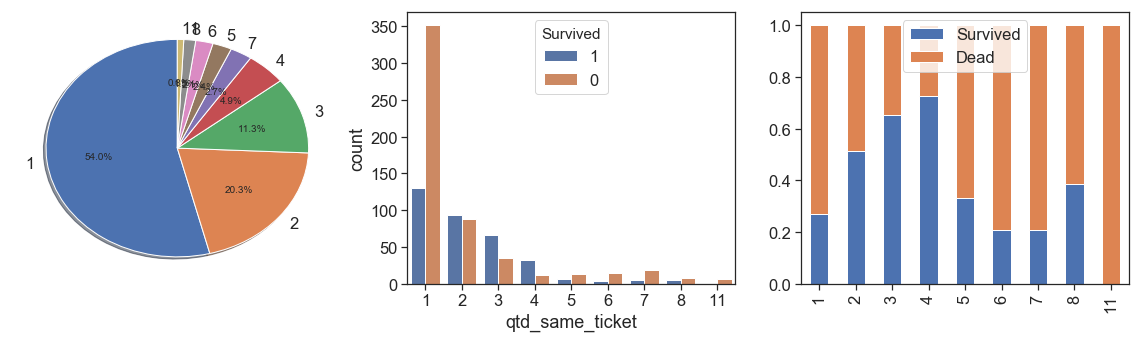
As we can see above:
- the majority (54%) bought only one ticket per passenger, and have lower survival rate than passengers that bought tickets for 2, 3, 4, 5 and 8 people.
- the survival rate is growing between 1 and 4, dropped a lot at 5. From the bar chart we can see that after 5 the number of samples is too low (84 out of 891, 9.4%, 1/4 of this is 5), and this data is skewed with a long tail to right. We can reduce this tail by binning all data after 4 in the same ordinal, its better to prevent overfitting, but we lose some others interesting case, see the next bullet. As alternative we can apply a box cox at this measure.
- The case of 11 people with same ticket probably is a huge family that all samples on the training data died. Let’s check this below.
data[(data.qtd_same_ticket==11)]
We confirm our hypothesis, and we notice that Fare is not the price of each passenger, but the price of each ticket, its total amount. Since our data is per passenger, this information has some distortion, because only one passenger that bought a ticket alone of 69.55 pounds is different from 11 passenger that bought a special ticket, with discount for group, by 6.32 pounds per passenger. It suggest to create a new feature that represents the real fare by passenger.
Back to the quantity of persons with same ticket, if we keep this and the model can capture this pattern, you’ll probably predict that the respective test samples also died! However, even if true, can be a sign of overfitting, because we only have 1.2% of these cases in the training samples.
In order to increase representativeness and lose the minimum of information, since we have only 44 (4.9%) training samples that bought tickets for 4 people and 101 (11.3%) of 3, we binning the quantity of 3 and 4 together as 3 (16,3%, over than 5 as 5 (84 samples). Let’s see the results below.
data['qtd_same_ticket_bin'] = data.qtd_same_ticket.apply(lambda x: 3 if (x>2 and x<5) else (5 if x>4 else x))
charts('qtd_same_ticket_bin', data[data.Survived>=0])
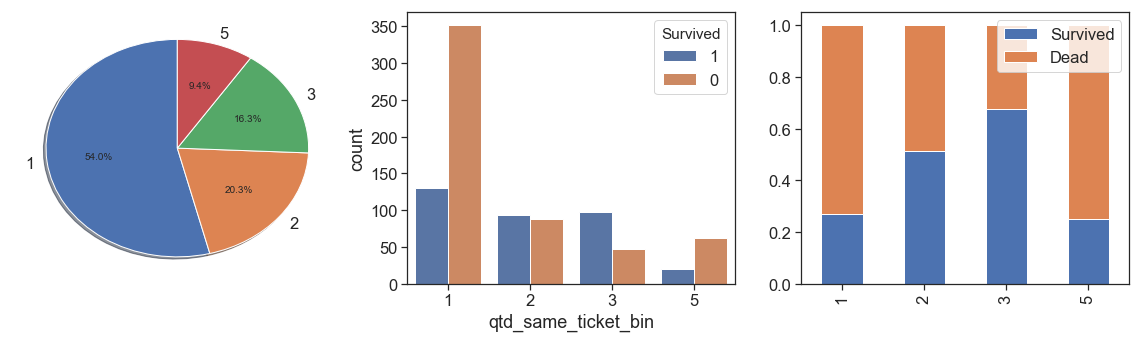
Other option, is create a binary feature that indicates if the passenger use a same ticket or not (not share his ticket)
print('Percent. survived from unique ticket: {:3.2%}'.\
format(data.Survived[(data.qtd_same_ticket==1) & (data.Survived>=0)].sum()/
data.Survived[(data.qtd_same_ticket==1) & (data.Survived>=0)].count()))
print('Percent. survived from same tickets: {:3.2%}'.\
format(data.Survived[(data.qtd_same_ticket>1) & (data.Survived>=0)].sum()/
data.Survived[(data.qtd_same_ticket>1) & (data.Survived>=0)].count()))
data['same_tckt'] = data.qtd_same_ticket.apply(lambda x: 1 if (x> 1) else 0)
charts('same_tckt', data[data.Survived>=0])
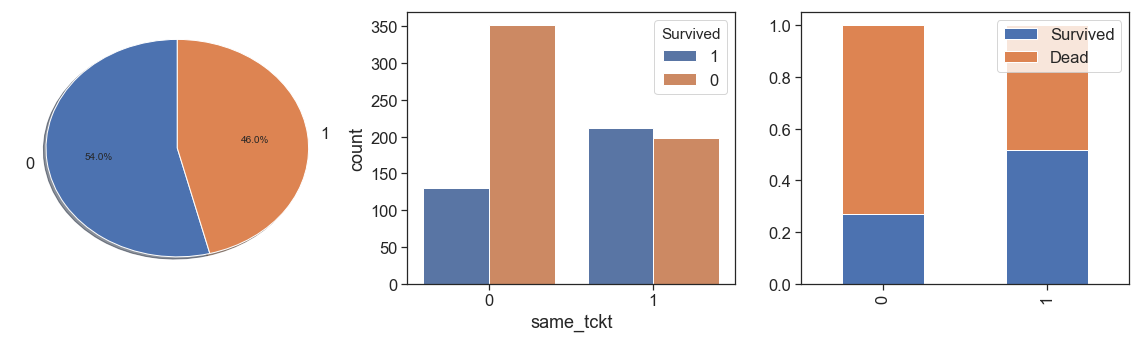
In this case we lose information that the chances of survival increase from 1 to 4, and fall from 5. In addition, cases 1 and 0 of the two measures are exactly the same. Then we will not use this option, and go work on Fare.
Finally, we have one more information to extract directly from Ticket, and check the possible special treatment!
data.Ticket.str.findall('[A-z]').apply(lambda x: ''.join(map(str, x))).value_counts().head(7)
data['distinction_in_tikect'] =\
(data.Ticket.str.findall('[A-z]').apply(lambda x: ''.join(map(str, x)).strip('[]')))
data.distinction_in_tikect = data.distinction_in_tikect.\
apply(lambda y: 'Without' if y=='' else y if (y in ['PC', 'CA', 'A', 'SOTONOQ', 'STONO', 'WC', 'SCPARIS']) else 'Others')
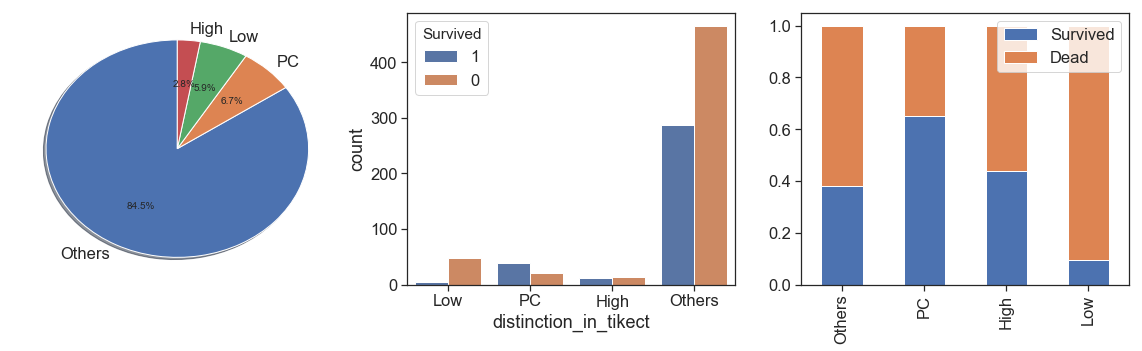
charts('distinction_in_tikect', data[(data.Survived>=0)])
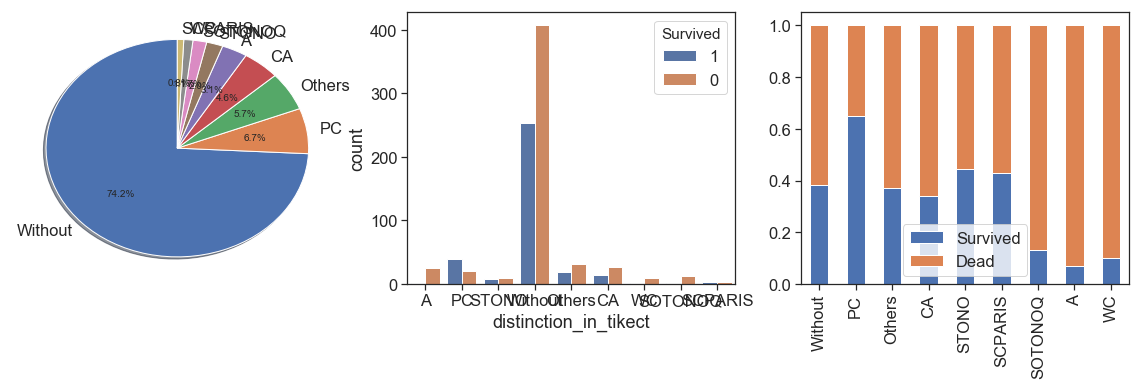
By the results, passengers with PC distinction in their tickets had best survival rate. Without, Others and CA is very close and can be grouped in one category and the we can do the same between STONO and SCAPARIS, and between A, SOTONOQ and WC.
data.distinction_in_tikect = data.distinction_in_tikect.\
apply(lambda y: 'Others' if (y in ['Without', 'Others', 'CA']) else\
'Low' if (y in ['A', 'SOTONOQ', 'WC']) else\
'High' if (y in ['STONO', 'SCPARIS']) else y)
charts('distinction_in_tikect', data[(data.Survived>=0)])
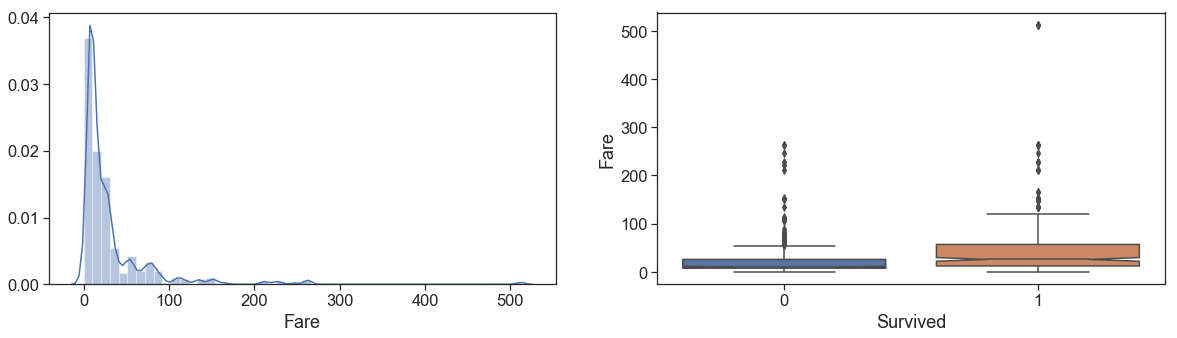
Fare¶
First, we treat the unique null fare case, then we take a look of the distribution of Fare (remember that is the total amount Fare of the Ticket).
# Fill null with median of most likely type passenger
data.loc[data.Fare.isnull(), 'Fare'] = data.Fare[(data.Pclass==3) & (data.qtd_same_ticket==1) & (data.Age>60)].median()
fig = plt.figure(figsize=(20,5))
f = fig.add_subplot(121)
g = sns.distplot(data[(data.Survived>=0)].Fare)
f = fig.add_subplot(122)
g = sns.boxplot(y='Fare', x='Survived', data=data[data.Survived>=0], notch = True)
Let’s take a look at how the fare per passenger is and how much it differs from the total
data['passenger_fare'] = data.Fare / data.qtd_same_ticket
fig = plt.figure(figsize=(20,6))
a = fig.add_subplot(141)
g = sns.distplot(data[(data.Survived>=0)].passenger_fare)
a = fig.add_subplot(142)
g = sns.boxplot(y='passenger_fare', x='Survived', data=data[data.Survived>=0], notch = True)
a = fig.add_subplot(143)
g = pd.qcut(data.Fare[(data.Survived==0)], q=[.0, .25, .50, .75, 1.00]).value_counts().plot(kind='bar', ax=a, title='Died')
a = fig.add_subplot(144)
g = pd.qcut(data.Fare[(data.Survived>0)], q=[.0, .25, .50, .75, 1.00]).value_counts().plot(kind='bar', ax=a, title='Survived')
plt.tight_layout(); plt.show()
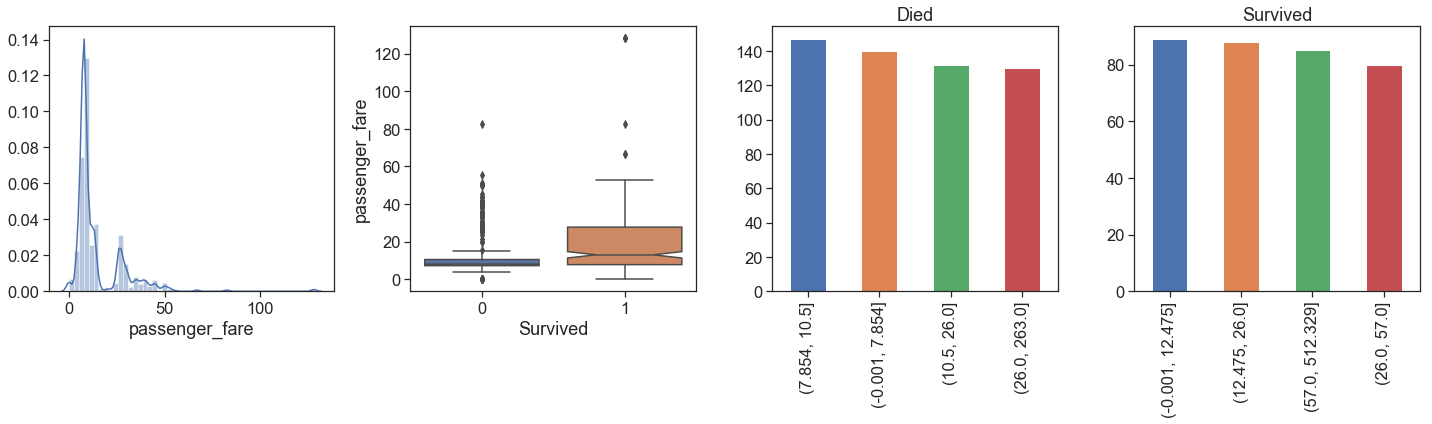

From the comparison, we can see that:
- the distributions are not exactly the same, with two spouts slightly apart on passenger fare.
- Class and how much paid per passenger make differences!
Although the number of survivors among the quartiles is approximately the same as expected, when we look at passenger fares, it is more apparent that the mortality rate is higher in the lower Fares, since the top of Q4 died is at the same height as the median plus a confidence interval of the fare paid by survivors.
- the number of outliers is lower in the fare per passenger, especially among survivors.
We can not rule out these outliers if there are cases of the same type in the test data set. In addition, these differences in values may be due to probably first class with additional fees for certain exclusives and cargo.
Below, you can see that the largest outlier all survival in the train data set, and has one case (1235 Passenger Id,
the matriarch of one son and two companions) to predict. Among all outlier cases of survivors, we see that all cases are first class, and different from the largest outlier, 27% actually died, and we have 18 cases to predict.
print('Passengers with higets passenger fare:')
display(data[data.passenger_fare>120])
print('\nSurivived of passenger fare more than 50:\n',
pd.pivot_table(data.loc[data.passenger_fare>50, ['Pclass', 'Survived']], aggfunc=np.count_nonzero,
columns=['Survived'] , index=['Pclass']))
Note that if we leave this way, if the model succeeds in capturing this pattern of largest outlier we are again thinking of a model that is at risk of overfitting (0.03% of cases).
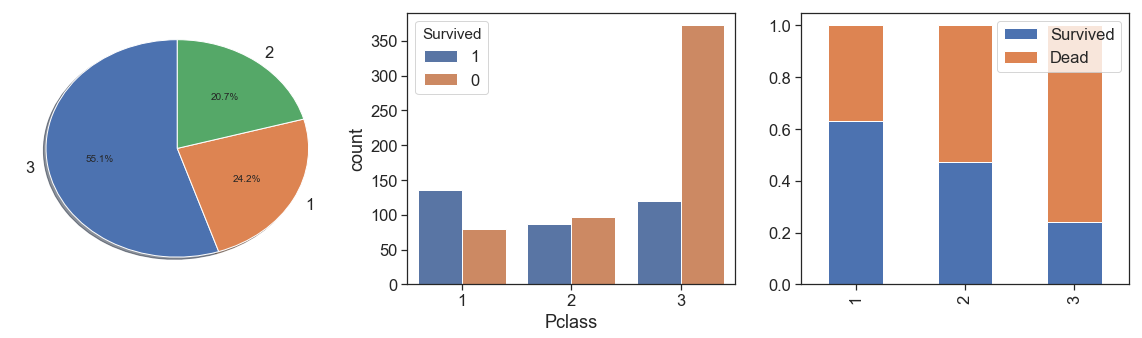
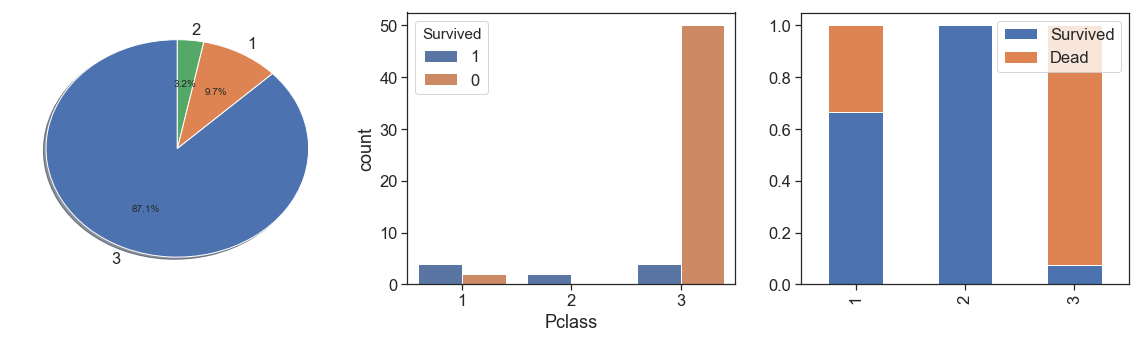
Pclass¶

Notwithstanding the fact that class 3 presents greater magnitude, as we see with Fare by passenger, we notice that survival rate is greater with greater fare by passenger. Its make to think that has some socioeconomic discrimination. It is confirmed when we saw the data distribution over the classes, and see the percent bar has a clearer aggressive decreasing survival rate through the first to the third classes.
charts('Pclass', data[(data.Survived>=0)])
SibSp¶

charts('SibSp', data[(data.Survived>=0)])
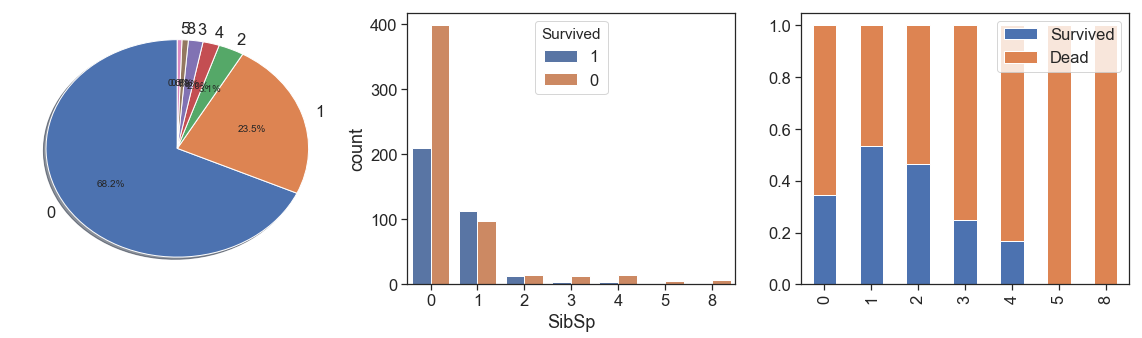
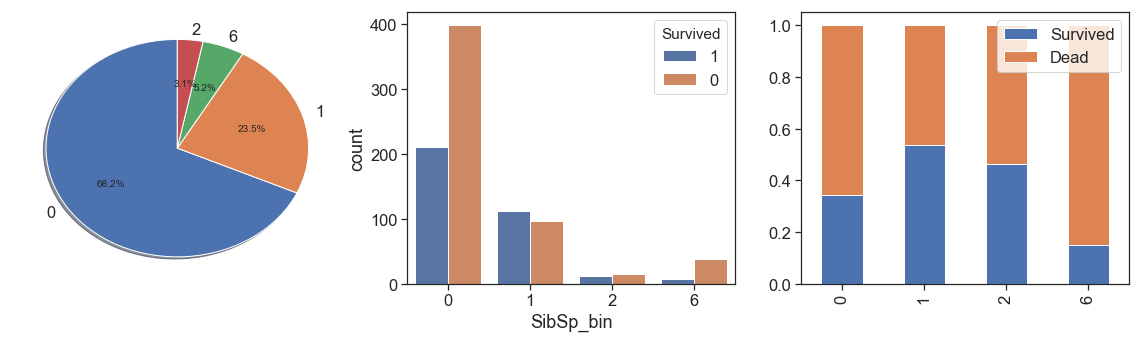
Since more than 2 siblings has too few cases and lowest survival rate, we can aggregate all this case into unique bin in order to increase representativeness and lose the minimum of information.
data['SibSp_bin'] = data.SibSp.apply(lambda x: 6 if x > 2 else x)
charts('SibSp_bin', data[(data.Survived>=0)])
Parch¶

charts('Parch', data[data.Survived>=0])
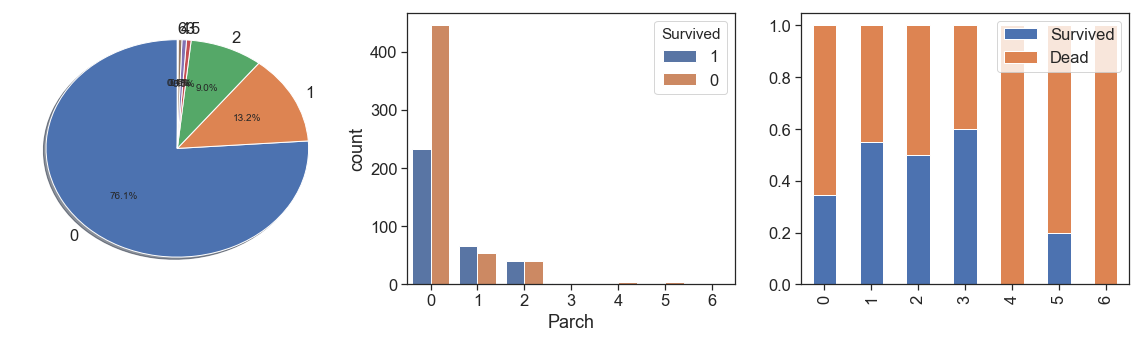
As we did with siblings, we will aggregate the Parch cases with more than 3, even with the highest survival rate with 3 Parch.
data['Parch_bin'] = data.Parch.apply(lambda x: x if x< 3 else 4)
charts('Parch_bin', data[(data.Survived>=0)])

Family and non-relatives¶
If you investigate the data, you will notice that total family members It can be obtained by the sum of Parch and SibSp plus 1 (1 for the person of respective record). So, let’s create the Family and see what we get.
data['family'] = data.SibSp + data.Parch + 1
charts('family', data[data.Survived>=0])
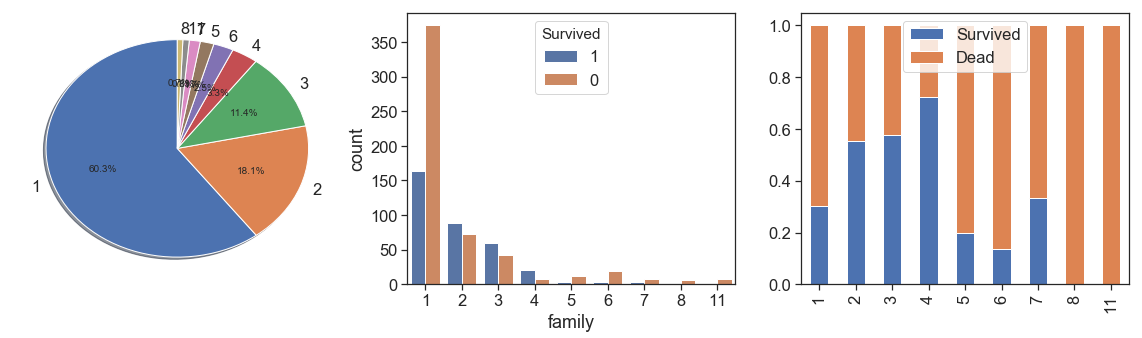
As we can see, family groups of up to 4 people were more likely to survive than people without relatives on board.
However from 5 family members we see a drastic fall and the leveling of the 7-member cases with the unfamiliar ones.
You may be led to think that this distortion clearly has some relation to the social condition. Better see the right data!
charts('Pclass', data[(data.family>4) & (data.Survived>=0)])

Yes, we have more cases in the third class, but on the other hand, what we see is that the numbers of cases with more than 4 relatives were rarer. n a more careful look, you will see that from 6 family members we only have third class (25 in training, 10 in test). So we confirmed that a large number of family members made a difference, yes, if you were from upper classes
You must have a feeling of déjà vu, and yes, this metric is very similar to the one we have already created, the amount of passengers with the same ticket.
So what’s the difference. At first you have only the amount of people aboard with family kinship plus herself, in the previous you have people reportedly grouped, family members or not. So, in cases where relatives bought tickets separately we see the family considering them, but the ticket separating them. On the other hand, as a family we do not consider travelers with their non-family companions, employees or friends, while in the other yes.
With this, we can now obtain the number of fellows or companions per passenger. This is the number of non-relatives who traveled with the passenger
data['non_relatives'] = data.qtd_same_ticket - data.family
charts('non_relatives', data[data.Survived>=0])

Here you see negative numbers because there are groups of travelers with the number of unrelated members larger than those with kinship.
Sex¶
As everybody knows, in that case women has more significant survival rate than men.
charts('Sex', data[(data.Survived>=0)])

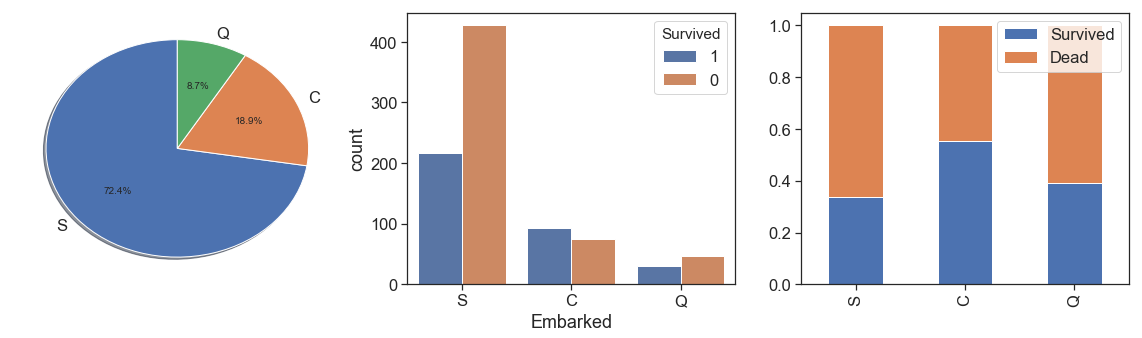
Embarked¶

First, we check the 2 embarked null cases to find the most likely pattern to considerate to fill with the respective mode.
In sequence, we take a look at the Embarked data. As we can see, the passengers that embarked from Cherbourg had best survival rates and most of the passengers embarked from Southampton and had the worst survival rate.
display(data[data.Embarked.isnull()])
data.loc[data.Embarked=='NA', 'Embarked'] = data[(data.Cabin.str.match('B2')>0) & (data.Pclass==1)].Embarked.mode()[0]
charts('Embarked', data[(data.Survived>=0)])
Name¶
![]()
Name feature has too much variance and is not significant, but has some value information to extracts and checks, like:
- Personal Titles
- Existence of nicknames
- Existence of references to another person
- Family names
def Personal_Titles(df):
df['Personal_Titles'] = df.Name.str.findall('Mrs\.|Mr\.|Miss\.|Maste[r]|Dr\.|Lady\.|Countess\.|'
+'Sir\.|Rev\.|Don\.|Major\.|Col\.|Jonkheer\.|'
+ 'Capt\.|Ms\.|Mme\.|Mlle\.').apply(lambda x: ''.join(map(str, x)).strip('[]'))
df.Personal_Titles[df.Personal_Titles=='Mrs.'] = 'Mrs'
df.Personal_Titles[df.Personal_Titles=='Mr.'] = 'Mr'
df.Personal_Titles[df.Personal_Titles=='Miss.'] = 'Miss'
df.Personal_Titles[df.Personal_Titles==''] = df[df.Personal_Titles==''].Sex.apply(lambda x: 'Mr' if (x=='male') else 'Mrs')
df.Personal_Titles[df.Personal_Titles=='Mme.'] = 'Mrs'
df.Personal_Titles[df.Personal_Titles=='Ms.'] = 'Mrs'
df.Personal_Titles[df.Personal_Titles=='Lady.'] = 'Royalty'
df.Personal_Titles[df.Personal_Titles=='Mlle.'] = 'Miss'
df.Personal_Titles[(df.Personal_Titles=='Miss.') & (df.Age>-1) & (df.Age<15)] = 'Kid'
df.Personal_Titles[df.Personal_Titles=='Master'] = 'Kid'
df.Personal_Titles[df.Personal_Titles=='Don.'] = 'Royalty'
df.Personal_Titles[df.Personal_Titles=='Jonkheer.'] = 'Royalty'
df.Personal_Titles[df.Personal_Titles=='Capt.'] = 'Technical'
df.Personal_Titles[df.Personal_Titles=='Rev.'] = 'Technical'
df.Personal_Titles[df.Personal_Titles=='Sir.'] = 'Royalty'
df.Personal_Titles[df.Personal_Titles=='Countess.'] = 'Royalty'
df.Personal_Titles[df.Personal_Titles=='Major.'] = 'Technical'
df.Personal_Titles[df.Personal_Titles=='Col.'] = 'Technical'
df.Personal_Titles[df.Personal_Titles=='Dr.'] = 'Technical'
Personal_Titles(data)
display(pd.pivot_table(data[['Personal_Titles', 'Survived']], aggfunc=np.count_nonzero,
columns=['Survived'] , index=['Personal_Titles']).T)
charts('Personal_Titles', data[(data.Survived>=0)])
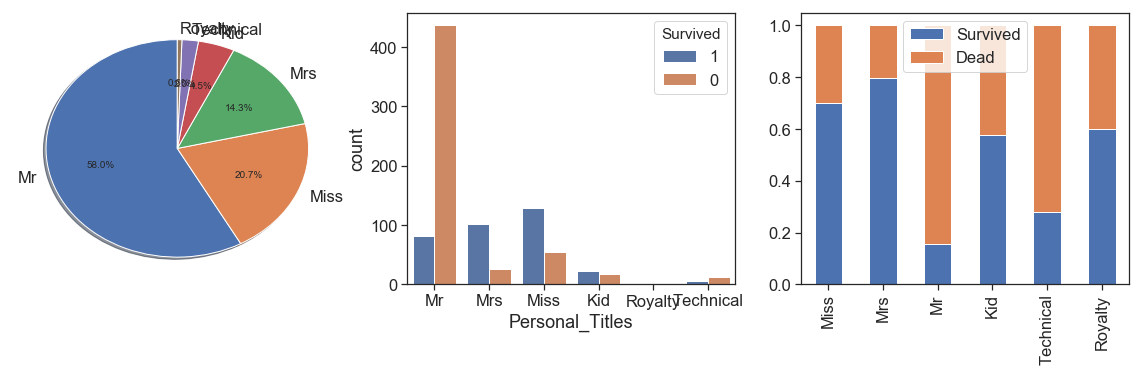
As you can see above, I opted to add some titles, but at first keep 2 small sets (Technical and Royalty), Because there are interesting survival rate variations.
Next, we identify the names with mentions to other people or with nicknames and create a boolean feature.
data['distinction_in_name'] =\
((data.Name.str.findall('\(').apply(lambda x: ''.join(map(str, x)).strip('[]'))=='(')
| (data.Name.str.findall(r'"[A-z"]*"').apply(lambda x: ''.join(map(str, x)).strip('""'))!=''))
data.distinction_in_name = data.distinction_in_name.apply(lambda x: 1 if x else 0)
charts('distinction_in_name', data[(data.Survived>=0)])
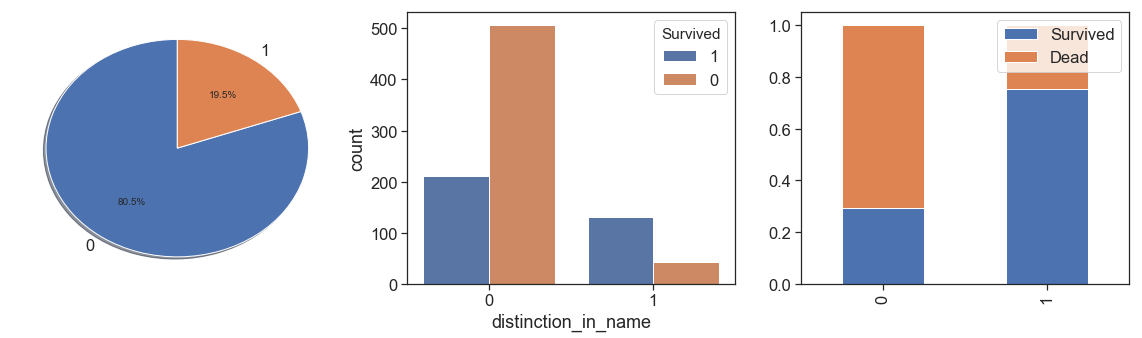
It is interesting to note that those who have some type of reference or distinction in their names had a higher survival rate.
Next, we find 872 surnames in this dataset. Even adding loners in a single category, we have 229 with more than one member. It’s a huge categorical data to work, and it is to much sparse. The most of then has too few samples to really has significances to almost of algorithms, without risk to occurs overfitting. In addition, there are 18 surnames cases with more than one member exclusively in the test data set.
So, we create this feature with aggregation of unique member into one category and use this at models that could work on it to check if we get better results. Alternatively, we can use dimensionality reduction methods.
print('Total of differents surnames aboard:',
((data.Name.str.findall(r'[A-z]*\,').apply(lambda x: ''.join(map(str, x)).strip(','))).value_counts()>1).shape[0])
print('More then one persons aboard with smae surnames:',
((data.Name.str.findall(r'[A-z]*\,').apply(lambda x: ''.join(map(str, x)).strip(','))).value_counts()>1).sum())
surnames = (data.Name.str.findall(r'[A-z]*\,').apply(lambda x: ''.join(map(str, x)).strip(','))).value_counts()
data['surname'] = (data.Name.str.findall(r'[A-z]*\,').\
apply(lambda x: ''.join(map(str, x)).strip(','))).apply(lambda x: x if surnames.get_value(x)>1 else 'Alone')
test_surnames = set(data.surname[data.Survived>=0].unique().tolist())
print('Surnames with more than one member aboard that happens only in the test data set:',
240-len(test_surnames))
train_surnames = set(data.surname[data.Survived<0].unique().tolist())
print('Surnames with more than one member aboard that happens only in the train data set:',
240-len(train_surnames))
both_surnames = test_surnames.intersection(train_surnames)
data.surname = data.surname.apply(lambda x : x if test_surnames.issuperset(set([x])) else 'Exclude')
del surnames, both_surnames, test_surnames, train_surnames
CabinByTicket = data.loc[~data.Cabin.isnull(), ['Ticket', 'Cabin']].groupby(by='Ticket').agg(min)
before = data.Cabin.isnull().sum()
data.loc[data.Cabin.isnull(), 'Cabin'] = data.loc[data.Cabin.isnull(), 'Ticket'].\
apply(lambda x: CabinByTicket[CabinByTicket.index==x].min())
print('Cabin nulls reduced:', (before - data.Cabin.isnull().sum()))
del CabinByTicket, before
data.Cabin[data.Cabin.isnull()] = 'N999'
data['Cabin_Letter'] = data.Cabin.str.findall('[^a-z]\d\d*')
data['Cabin_Number'] = data.apply(lambda x: 0 if len(str(x.Cabin))== 1 else np.int(np.int(x.Cabin_Letter[0][1:])/10), axis=1)
data.Cabin_Letter = data.apply(lambda x: x.Cabin if len(str(x.Cabin))== 1 else x.Cabin_Letter[0][0], axis=1)
display(data[['Fare', 'Cabin_Letter']].groupby(['Cabin_Letter']).agg([np.median, np.mean, np.count_nonzero, np.max, np.min]))
Doesn’t exist Cabin T in test dataset. This passenger is from first class and his passenger fare is the same from others 5 first class passengers. So, changed to ‘C’ to made same distribution between the six.
display(data[data.Cabin=='T'])
display(data.Cabin_Letter[data.passenger_fare==35.5].value_counts())
data.Cabin_Letter[data.Cabin_Letter=='T'] = 'C'
Fill Cabins letters NAs of third class with most common patterns of the same passenger fare range with one or lessen possible cases.
data.loc[(data.passenger_fare<6.237) & (data.passenger_fare>=0.0) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare<6.237) & (data.passenger_fare>=0.0) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare<6.237) & (data.passenger_fare>=0.0) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare<6.237) & (data.passenger_fare>=0.0) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare<7.225) & (data.passenger_fare>=6.237) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare<7.225) & (data.passenger_fare>=6.237) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare<7.225) & (data.passenger_fare>=6.237) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare<7.225) & (data.passenger_fare>=6.237) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare<7.65) & (data.passenger_fare>=7.225) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare<7.65) & (data.passenger_fare>=7.225) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare<7.65) & (data.passenger_fare>=7.225) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare<7.65) & (data.passenger_fare>=7.225) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.min()
data.loc[(data.passenger_fare<7.75) & (data.passenger_fare>=7.65) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare<7.75) & (data.passenger_fare>=7.65) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare<7.75) & (data.passenger_fare>=7.65) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare<7.75) & (data.passenger_fare>=7.65) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.min()
data.loc[(data.passenger_fare<8.0) & (data.passenger_fare>=7.75) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare<8.0) & (data.passenger_fare>=7.75) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare<8.0) & (data.passenger_fare>=7.75) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare<8.0) & (data.passenger_fare>=7.75) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.min()
data.loc[(data.passenger_fare>=8.0) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=8.0) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=8.0) & (data.Pclass==3) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=8.0) & (data.Pclass==3) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
Fill Cabins letters NAs of second class with most common patterns of the same passenger fare range with one or lessen possible cases.
data.loc[(data.passenger_fare>=0) & (data.passenger_fare<8.59) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=0) & (data.passenger_fare<8.59) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=0) & (data.passenger_fare<8.59) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=0) & (data.passenger_fare<8.59) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=8.59) & (data.passenger_fare<10.5) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=8.59) & (data.passenger_fare<10.5) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=8.59) & (data.passenger_fare<10.5) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=8.59) & (data.passenger_fare<10.5) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=10.5) & (data.passenger_fare<10.501) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=10.5) & (data.passenger_fare<10.501) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=10.5) & (data.passenger_fare<10.501) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=10.5) & (data.passenger_fare<10.501) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=10.501) & (data.passenger_fare<12.5) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=10.501) & (data.passenger_fare<12.5) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=10.501) & (data.passenger_fare<12.5) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=10.501) & (data.passenger_fare<12.5) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=12.5) & (data.passenger_fare<13.) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=12.5) & (data.passenger_fare<13.) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=12.5) & (data.passenger_fare<13.) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=12.5) & (data.passenger_fare<13.) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=13.) & (data.passenger_fare<13.1) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=13.) & (data.passenger_fare<13.1) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=13.) & (data.passenger_fare<13.1) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=13.) & (data.passenger_fare<13.1) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>=13.1) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>=13.1) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>=13.1) & (data.Pclass==2) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>=13.1) & (data.Pclass==2) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
Fill Cabins letters NAs of first class with most common patterns of the same passenger fare range with one or lessen possible cases.
data.loc[(data.passenger_fare==0) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare==0) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare==0) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare==0) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>0) & (data.passenger_fare<=19.69) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>0) & (data.passenger_fare<=19.69) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>0) & (data.passenger_fare<=19.69) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>0) & (data.passenger_fare<=19.69) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>19.69) & (data.passenger_fare<=23.374) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>19.69) & (data.passenger_fare<=23.374) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>19.69) & (data.passenger_fare<=23.374) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>19.69) & (data.passenger_fare<=23.374) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>23.374) & (data.passenger_fare<=25.25) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>23.374) & (data.passenger_fare<=25.25) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>23.374) & (data.passenger_fare<=25.25) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>23.374) & (data.passenger_fare<=25.25) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>25.69) & (data.passenger_fare<=25.929) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>25.69) & (data.passenger_fare<=25.929) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>25.69) & (data.passenger_fare<=25.929) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>25.69) & (data.passenger_fare<=25.929) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>25.99) & (data.passenger_fare<=26.) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>25.99) & (data.passenger_fare<=26.) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>25.99) & (data.passenger_fare<=26.) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>25.99) & (data.passenger_fare<=26.) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>26.549) & (data.passenger_fare<=26.55) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>26.549) & (data.passenger_fare<=26.55) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>26.549) & (data.passenger_fare<=26.55) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>26.549) & (data.passenger_fare<=26.55) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>27.4) & (data.passenger_fare<=27.5) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>27.4) & (data.passenger_fare<=27.5) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>27.4) & (data.passenger_fare<=27.5) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>27.4) & (data.passenger_fare<=27.5) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>27.7207) & (data.passenger_fare<=27.7208) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>27.7207) & (data.passenger_fare<=27.7208) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>27.7207) & (data.passenger_fare<=27.7208) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>27.7207) & (data.passenger_fare<=27.7208) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>29.69) & (data.passenger_fare<=29.7) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>29.69) & (data.passenger_fare<=29.7) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>29.69) & (data.passenger_fare<=29.7) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>29.69) & (data.passenger_fare<=29.7) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>30.49) & (data.passenger_fare<=30.5) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>30.49) & (data.passenger_fare<=30.5) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>30.49) & (data.passenger_fare<=30.5) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>30.49) & (data.passenger_fare<=30.5) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>30.6) & (data.passenger_fare<=30.7) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>30.6) & (data.passenger_fare<=30.7) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>30.6) & (data.passenger_fare<=30.7) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>30.6) & (data.passenger_fare<=30.7) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>31.67) & (data.passenger_fare<=31.684) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>31.67) & (data.passenger_fare<=31.684) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>31.67) & (data.passenger_fare<=31.684) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>31.67) & (data.passenger_fare<=31.684) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>39.599) & (data.passenger_fare<=39.6) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>39.599) & (data.passenger_fare<=39.6) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>39.599) & (data.passenger_fare<=39.6) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>39.599) & (data.passenger_fare<=39.6) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>41) & (data.passenger_fare<=41.2) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>41) & (data.passenger_fare<=41.2) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>41) & (data.passenger_fare<=41.2) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>41) & (data.passenger_fare<=41.2) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>45.49) & (data.passenger_fare<=45.51) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>45.49) & (data.passenger_fare<=45.51) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>45.49) & (data.passenger_fare<=45.51) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>45.49) & (data.passenger_fare<=45.51) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>49.5) & (data.passenger_fare<=49.51) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>49.5) & (data.passenger_fare<=49.51) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>49.5) & (data.passenger_fare<=49.51) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>49.5) & (data.passenger_fare<=49.51) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
data.loc[(data.passenger_fare>65) & (data.passenger_fare<=70) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Letter'] =\
data[(data.passenger_fare>65) & (data.passenger_fare<=70) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Letter.mode()[0]
data.loc[(data.passenger_fare>65) & (data.passenger_fare<=70) & (data.Pclass==1) & (data.Cabin=='N999'), 'Cabin_Number'] =\
data[(data.passenger_fare>65) & (data.passenger_fare<=70) & (data.Pclass==1) & (data.Cabin!='N999')].Cabin_Number.mode()[0]
See below that we conquered a good results after filling nulls, but we need attention since they have too many nulls originally. In addition, the cabin may actually have made more difference in the deaths caused by the impact and not so much among those who drowned.
charts('Cabin_Letter', data[(data.Survived>=0)])

Rescue of family relationships¶

After some work, we notice that is difficult to understand SibSp and Patch isolated, and is difficult to extract directly families relationships from this data without a closer look.
So, in that configuration we not have clearly families relationships, and this information is primary to use for apply ages to ages with null with better distribution and accuracy.
Let’s start to rescue:
The first treatment, I discovered when check the results and noticed that I didn’t apply any relationship to a one case. Look the details below, we can see that is a case of a family with more than one ticket and the son has no age. So, I just manually applied this one case as a son, since the others member the father and the mother, and the son has the pattern 0 in SibSp and Parch 2
display(data[data.Name.str.findall('Bourke').apply(lambda x: ''.join(map(str, x)).strip('[]'))=='Bourke'])
family_w_age = data.Ticket[(data.Parch>0) & (data.SibSp>0) & (data.Age==-1)].unique().tolist()
data[data.Ticket.isin(family_w_age)].sort_values('Ticket')
data['sons'] = data.apply(lambda x : \
1 if ((x.Ticket in (['2661', '2668', 'A/5. 851', '4133'])) & (x.SibSp>0)) else 0, axis=1)
data.sons += data.apply(lambda x : \
1 if ((x.Ticket in (['CA. 2343'])) & (x.SibSp>1)) else 0, axis=1)
data.sons += data.apply(lambda x : \
1 if ((x.Ticket in (['W./C. 6607'])) & (x.Personal_Titles not in (['Mr', 'Mrs']))) else 0, axis=1)
data.sons += data.apply(lambda x: 1 if ((x.Parch>0) & (x.Age>=0) & (x.Age<20)) else 0, axis=1)
data.sons.loc[data.PassengerId==594] = 1 # Sun with diferente pattern (family with two tickets)
data.sons.loc[data.PassengerId==1252] = 1 # Case of 'CA. 2343' and last rule
data.sons.loc[data.PassengerId==1084] = 1 # Case of 'A/5. 851' and last rule
data.sons.loc[data.PassengerId==1231] = 1 # Case of 'A/5. 851' and last rule
charts('sons', data[(data.Survived>=0)])
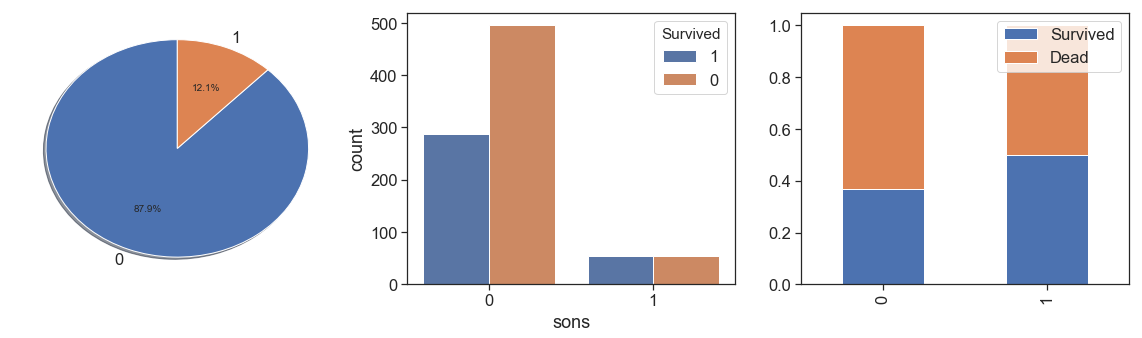
We observe that has only 12.1% of sons, and their had better survival rate than others.
Next, we rescue the parents, and check cases where we have both (mother and father), and cases where we have only one aboard.
data['parents'] = data.apply(lambda x : \
1 if ((x.Ticket in (['2661', '2668', 'A/5. 851', '4133'])) & (x.SibSp==0)) else 0, axis=1)
data.parents += data.apply(lambda x : \
1 if ((x.Ticket in (['CA. 2343'])) & (x.SibSp==1)) else 0, axis=1)
data.parents += data.apply(lambda x : 1 if ((x.Ticket in (['W./C. 6607'])) & (x.Personal_Titles in (['Mr', 'Mrs']))) \
else 0, axis=1)
# Identify parents and care nulls ages
data.parents += data.apply(lambda x: 1 if ((x.Parch>0) & (x.SibSp>0) & (x.Age>19) & (x.Age<=45) ) else 0, axis=1)
charts('parents', data[(data.Survived>=0)])
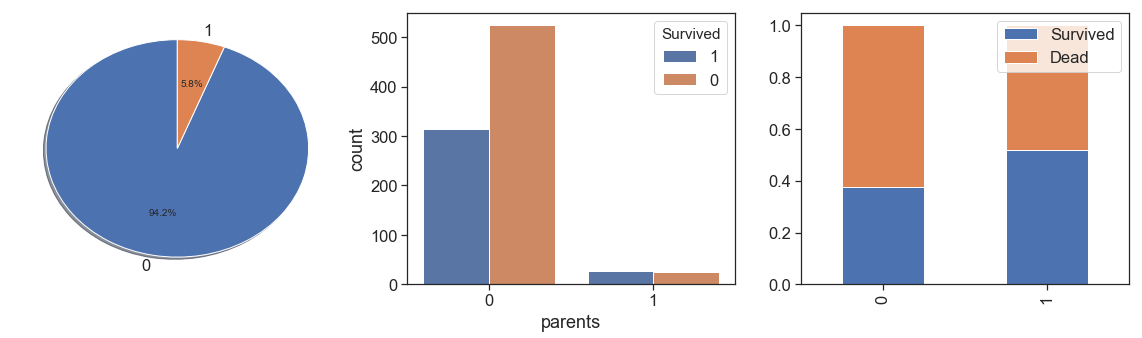
data['parent_alone'] = data.apply(lambda x: 1 if ((x.Parch>0) & (x.SibSp==0) & (x.Age>19) & (x.Age<=45) ) else 0, axis=1)
charts('parent_alone', data[(data.Survived>=0)])
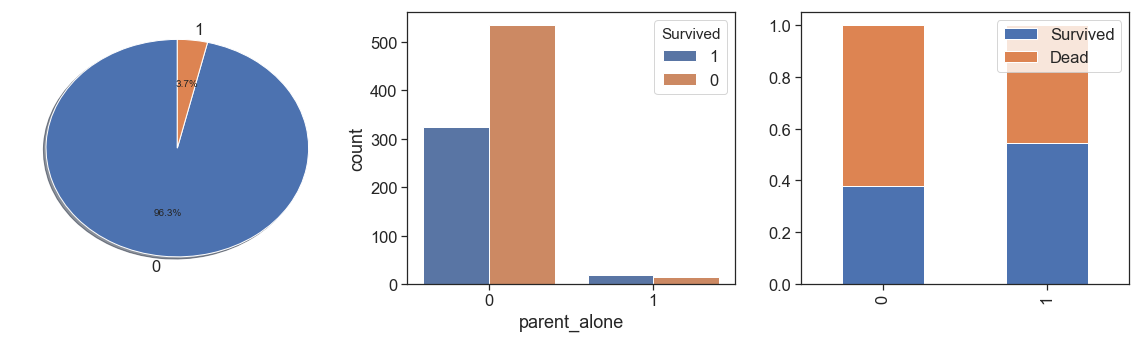
We can notice that the both cases are to similar and it is not significant to has this two information separately.
Before I put them together, as I had learned in assembling the sons, I made a visual inspection and discovered some cases of sons and parents that required different rules for assigning them. As I did visually and this is not a rule for a pipeline, I proceeded with the settings manually.
t_p_alone = data.Ticket[data.parent_alone==1].tolist()
data[data.Ticket.isin(t_p_alone)].sort_values('Ticket')[96:]
data.parent_alone.loc[data.PassengerId==141] = 1
data.parent_alone.loc[data.PassengerId==541] = 0
data.sons.loc[data.PassengerId==541] = 1
data.parent_alone.loc[data.PassengerId==1078] = 0
data.sons.loc[data.PassengerId==1078] = 1
data.parent_alone.loc[data.PassengerId==98] = 0
data.sons.loc[data.PassengerId==98] = 1
data.parent_alone.loc[data.PassengerId==680] = 0
data.sons.loc[data.PassengerId==680] = 1
data.parent_alone.loc[data.PassengerId==915] = 0
data.sons.loc[data.PassengerId==915] = 1
data.parent_alone.loc[data.PassengerId==333] = 0
data.sons.loc[data.PassengerId==333] = 1
data.parent_alone.loc[data.PassengerId==119] = 0
data.sons[data.PassengerId==119] = 1
data.parent_alone.loc[data.PassengerId==319] = 0
data.sons.loc[data.PassengerId==319] = 1
data.parent_alone.loc[data.PassengerId==103] = 0
data.sons.loc[data.PassengerId==103] = 1
data.parents.loc[data.PassengerId==154] = 0
data.sons.loc[data.PassengerId==1084] = 1
data.parents.loc[data.PassengerId==581] = 0
data.sons.loc[data.PassengerId==581] = 1
data.parent_alone.loc[data.PassengerId==881] = 0
data.sons.loc[data.PassengerId==881] = 1
data.parent_alone.loc[data.PassengerId==1294] = 0
data.sons.loc[data.PassengerId==1294] = 1
data.parent_alone.loc[data.PassengerId==378] = 0
data.sons.loc[data.PassengerId==378] = 1
data.parent_alone.loc[data.PassengerId==167] = 1
data.parent_alone.loc[data.PassengerId==357] = 0
data.sons.loc[data.PassengerId==357] = 1
data.parent_alone.loc[data.PassengerId==918] = 0
data.sons.loc[data.PassengerId==918] = 1
data.parent_alone.loc[data.PassengerId==1042] = 0
data.sons.loc[data.PassengerId==1042] = 1
data.parent_alone.loc[data.PassengerId==540] = 0
data.sons.loc[data.PassengerId==540] = 1
data.parents += data.parent_alone
charts('parents', data[(data.Survived>=0)])

Next, we rescue the grandparents and grandparents alone. We found the same situations with less cases and decided put all parents and grandparents in one feature and leave to age distinguish them.
data['grandparents'] = data.apply(lambda x: 1 if ((x.Parch>0) & (x.SibSp>0) & (x.Age>19) & (x.Age>45) ) else 0, axis=1)
charts('grandparents', data[(data.Survived>=0)])
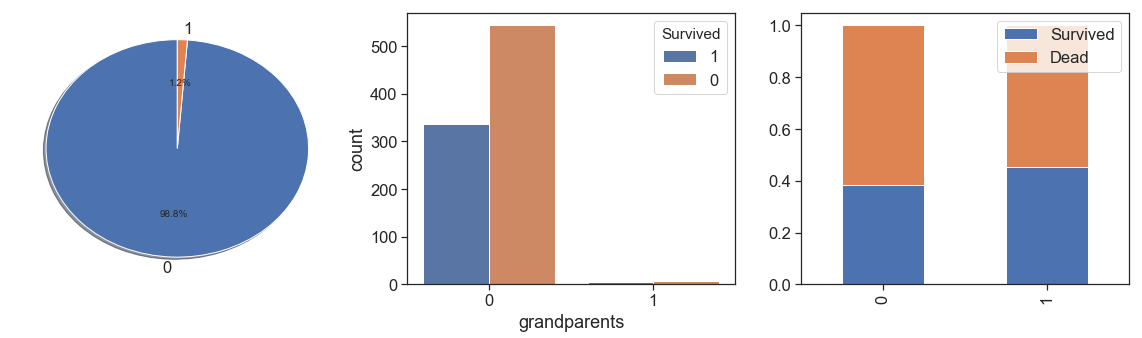
data['grandparent_alone'] = data.apply(lambda x: 1 if ((x.Parch>0) & (x.SibSp==0) & (x.Age>45) ) else 0, axis=1)
charts('grandparent_alone', data[(data.Survived>=0)])
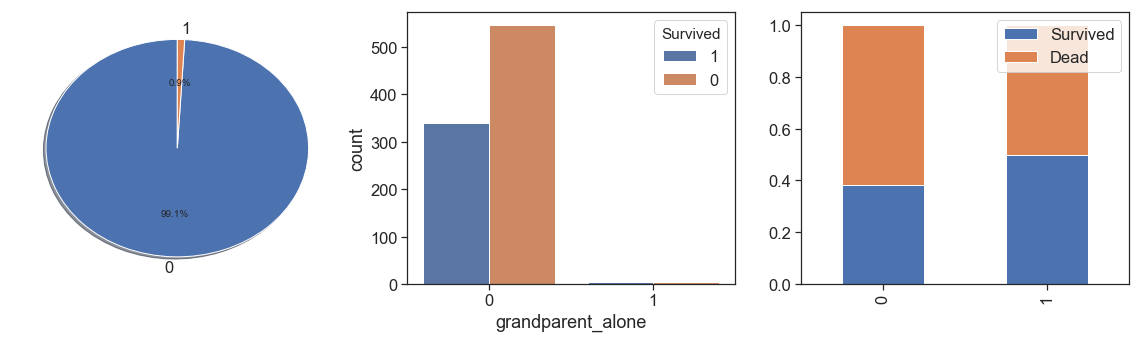
data.parents += data.grandparent_alone + data.grandparents
charts('parents', data[(data.Survived>=0)])

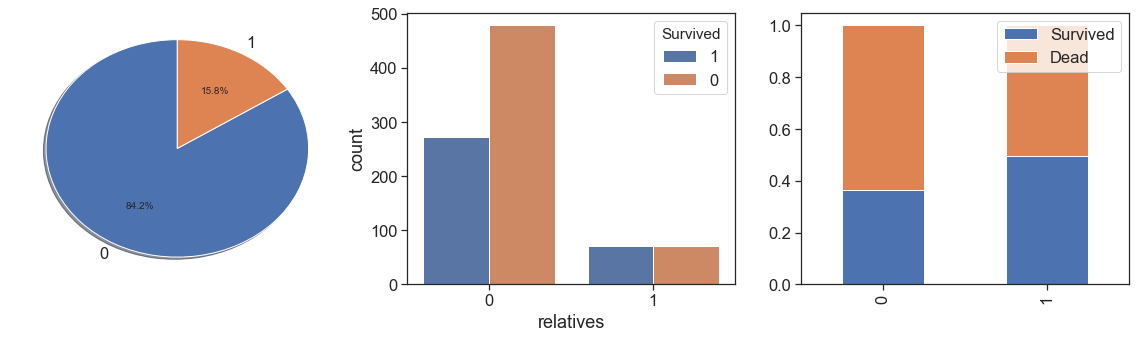
Next, we identify the relatives aboard:
data['relatives'] = data.apply(lambda x: 1 if ((x.SibSp>0) & (x.Parch==0)) else 0, axis=1)
charts('relatives', data[(data.Survived>=0)])
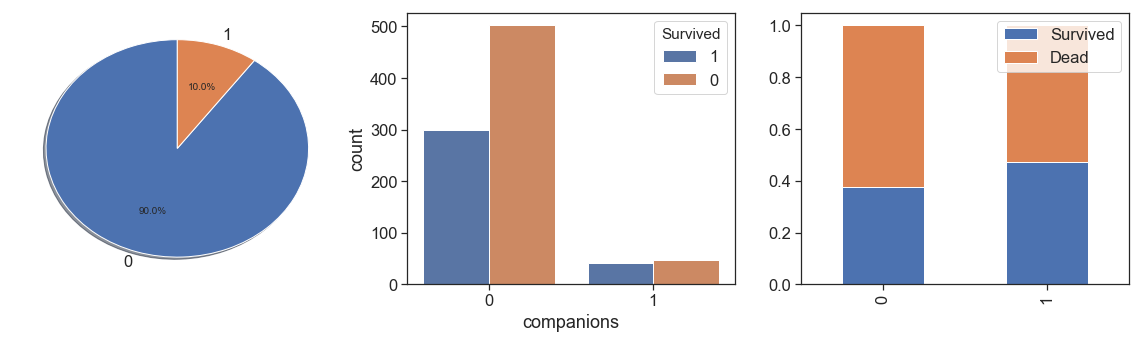
And then, the companions, persons who traveled with a family but do not have family relationship with them.
data['companions'] = data.apply(lambda x: 1 if ((x.SibSp==0) & (x.Parch==0) & (x.same_tckt==1)) else 0, axis=1)
charts('companions', data[(data.Survived>=0)])
Finally, we rescue the passengers that traveled alone.
data['alone'] = data.apply(lambda x: 1 if ((x.SibSp==0) & (x.Parch==0) & (x.same_tckt==0)) else 0, axis=1)
charts('alone', data[(data.Survived>=0)])
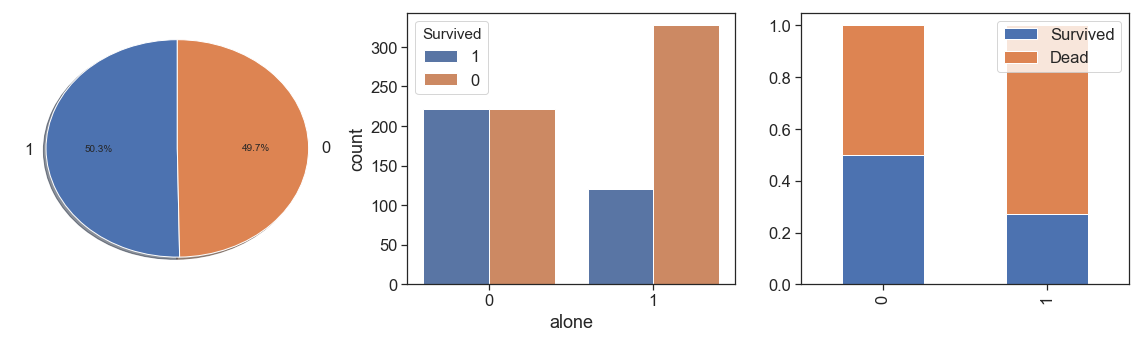
As we can see, people with a family relationship, even if only as companions, had better survival rates and very close, than people who traveled alone.
Now we can work on issues of nulls ages and then on own information of age.
Age¶

We start with the numbers of nulls case by survived to remember that is too high.
Then, we plot the distributions of Ages, to check how is fit into the normal and see the distortions when apply a unique value (zero) to the nulls cases.
Next, we made the scatter plot of Ages and siblings, and see hat age decreases with the increase in the number of siblings, but with a great range
fig = plt.figure(figsize=(20, 10))
fig1 = fig.add_subplot(221)
g = sns.distplot(data.Age.fillna(0), fit=norm, label='Nulls as Zero')
g = sns.distplot(data[~data.Age.isnull()].Age, fit=norm, label='Withou Nulls')
plt.legend(loc='upper right')
print('Survived without Age:')
display(data[data.Age.isnull()].Survived.value_counts())
fig2 = fig.add_subplot(222)
g = sns.scatterplot(data = data[(~data.Age.isnull())], y='Age', x='SibSp', hue='Survived')
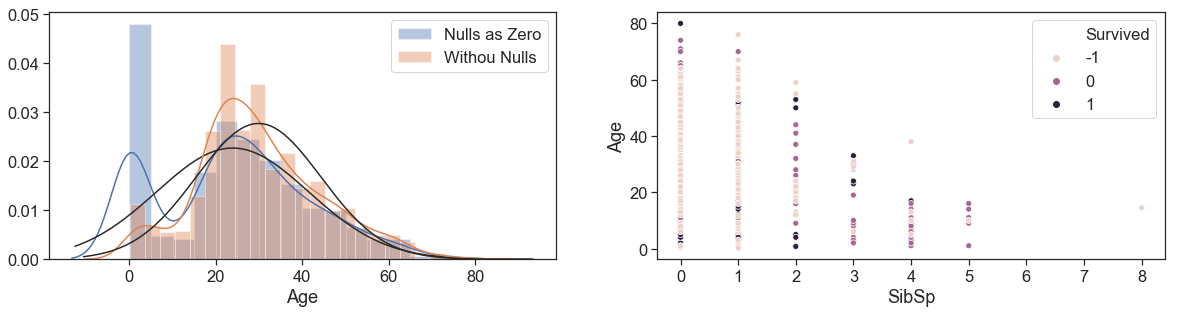
From the tables below, we can see that our enforce to get Personal Titles and rescue family relationships produce better medians to apply on nulls ages.
print('Mean and median ages by siblings:')
data.loc[data.Age.isnull(), 'Age'] = -1
display(data.loc[(data.Age>=0), ['SibSp', 'Age']].groupby('SibSp').agg([np.mean, np.median]).T)
print('\nMedian ages by Personal_Titles:')
Ages = { 'Age' : {'median'}}
display(data[data.Age>=0][['Age', 'Personal_Titles', 'parents', 'grandparents', 'sons', 'relatives', 'companions', 'alone']].\
groupby('Personal_Titles').agg(Ages).T)
print('\nMedian ages by Personal Titles and Family Relationships:')
display(pd.pivot_table(data[data.Age>=0][['Age', 'Personal_Titles', 'parents', 'grandparents',
'sons', 'relatives', 'companions','alone']],
aggfunc=np.median,
index=['parents', 'grandparents', 'sons', 'relatives', 'companions', 'alone'] ,
columns=['Personal_Titles']))
print('\nNulls ages by Personal Titles and Family Relationships:')
display(data[data.Age<0][['Personal_Titles', 'parents', 'grandparents', 'sons', 'relatives', 'companions', 'alone']].\
groupby('Personal_Titles').agg([sum]))
So, we apply to the nulls ages the respectively median of same personal title and same family relationship, but before, we create a binary feature to maintain the information of the presence of nulls.
data['Without_Age'] = data.Age.apply(lambda x: 0 if x>0 else 1)
data.Age.loc[(data.Age<0) & (data.companions==1) & (data.Personal_Titles=='Miss')] = \
data.Age[(data.Age>=0) & (data.companions==1) & (data.Personal_Titles=='Miss')].median()
data.Age.loc[(data.Age<0) & (data.companions==1) & (data.Personal_Titles=='Mr')] = \
data.Age[(data.Age>=0) & (data.companions==1) & (data.Personal_Titles=='Mr')].median()
data.Age.loc[(data.Age<0) & (data.companions==1) & (data.Personal_Titles=='Mrs')] = \
data.Age[(data.Age>=0) & (data.companions==1) & (data.Personal_Titles=='Mrs')].median()
data.Age.loc[(data.Age<0) & (data.alone==1) & (data.Personal_Titles=='Kid')] = \
data.Age[(data.Age>=0) & (data.alone==1) & (data.Personal_Titles=='Kid')].median()
data.Age.loc[(data.Age<0) & (data.alone==1) & (data.Personal_Titles=='Technical')] = \
data.Age[(data.Age>=0) & (data.alone==1) & (data.Personal_Titles=='Technical')].median()
data.Age.loc[(data.Age<0) & (data.alone==1) & (data.Personal_Titles=='Miss')] = \
data.Age[(data.Age>=0) & (data.alone==1) & (data.Personal_Titles=='Miss')].median()
data.Age.loc[(data.Age<0) & (data.alone==1) & (data.Personal_Titles=='Mr')] = \
data.Age[(data.Age>=0) & (data.alone==1) & (data.Personal_Titles=='Mr')].median()
data.Age.loc[(data.Age<0) & (data.alone==1) & (data.Personal_Titles=='Mrs')] = \
data.Age[(data.Age>=0) & (data.alone==1) & (data.Personal_Titles=='Mrs')].median()
data.Age.loc[(data.Age<0) & (data.parents==1) & (data.Personal_Titles=='Mr')] = \
data.Age[(data.Age>=0) & (data.parents==1) & (data.Personal_Titles=='Mr')].median()
data.Age.loc[(data.Age<0) & (data.parents==1) & (data.Personal_Titles=='Mrs')] = \
data.Age[(data.Age>=0) & (data.parents==1) & (data.Personal_Titles=='Mrs')].median()
data.Age.loc[(data.Age<0) & (data.sons==1) & (data.Personal_Titles=='Kid')] = \
data.Age[(data.Age>=0) & (data.Personal_Titles=='Kid')].median()
data.Age.loc[(data.Age.isnull()) & (data.sons==1) & (data.Personal_Titles=='Kid')] = \
data.Age[(data.Age>=0) & (data.Personal_Titles=='Kid')].median()
data.Age.loc[(data.Age<0) & (data.sons==1) & (data.Personal_Titles=='Miss')] = \
data.Age[(data.Age>=0) & (data.sons==1) & (data.Personal_Titles=='Miss')].median()
data.Age.loc[(data.Age<0) & (data.sons==1) & (data.Personal_Titles=='Mr')] = \
data.Age[(data.Age>=0) & (data.sons==1) & (data.Personal_Titles=='Mr')].median()
data.Age.loc[(data.Age<0) & (data.sons==1) & (data.Personal_Titles=='Mrs')] = \
data.Age[(data.Age>=0) & (data.sons==1) & (data.Personal_Titles=='Mrs')].median()
data.Age.loc[(data.Age<0) & (data.relatives==1) & (data.Personal_Titles=='Miss')] = \
data.Age[(data.Age>=0) & (data.relatives==1) & (data.Personal_Titles=='Miss')].median()
data.Age.loc[(data.Age<0) & (data.relatives==1) & (data.Personal_Titles=='Mr')] = \
data.Age[(data.Age>=0) & (data.sons==1) & (data.Personal_Titles=='Mr')].median()
data.Age.loc[(data.Age<0) & (data.relatives==1) & (data.Personal_Titles=='Mrs')] = \
data.Age[(data.Age>=0) & (data.relatives==1) & (data.Personal_Titles=='Mrs')].median()
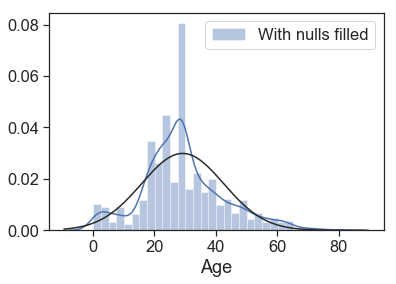
Finally, we check how age distribution lines after fill the nulls.
print('Age correlation with survived:',data.corr()['Survived'].Age)
g = sns.distplot(data.Age, fit=norm, label='With nulls filled')
plt.legend(loc='upper right')
plt.show()
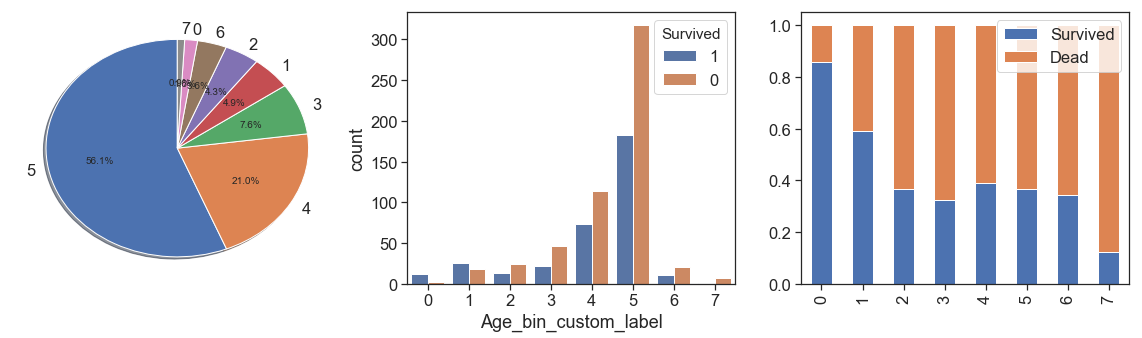
To have better understanding of age, its proportion and its relation to survival ration, we binning it as follow
def binningAge(df):
# Binning Age based on custom ranges
bin_ranges = [0, 1.7, 8, 15, 18, 25, 55, 65, 100]
bin_names = [0, 1, 2, 3, 4, 5, 6, 7]
df['Age_bin_custom_range'] = pd.cut(np.array(df.Age), bins=bin_ranges)
df['Age_bin_custom_label'] = pd.cut(np.array(df.Age), bins=bin_ranges, labels=bin_names)
return df
data = binningAge(data)
display(data[['Age', 'Age_bin_custom_range', 'Age_bin_custom_label']].sample(5))
display(pd.pivot_table(data[['Age_bin_custom_range', 'Survived']], aggfunc=np.count_nonzero,
index=['Survived'] , columns=['Age_bin_custom_range']))
charts('Age_bin_custom_label', data[(data.Survived>=0)])
One hot encode and drop provisory and useless features¶
One hot encode categorical and non ordinal data and drop useless features.
data['genre'] = data.Sex.apply(lambda x: 1 if x=='male' else 0)
data.drop(['Name', 'Cabin', 'Ticket', 'Sex', 'same_tckt', 'qtd_same_ticket', 'parent_alone', 'grandparents',
'grandparent_alone', 'Age_bin_custom_range'], axis=1, inplace=True) # , 'Age', 'Parch', 'SibSp',
data = pd.get_dummies(data, columns = ['Cabin_Letter', 'Personal_Titles', 'Embarked', 'distinction_in_tikect'])
data = pd.get_dummies(data, columns = ['surname']) # 'Age_bin_custom_label'
data.drop(['surname_Exclude'], axis=1, inplace=True)
Scipy‘s pearson method computes both the correlation and p-value for the correlation, roughly showing the probability of an uncorrelated system creating a correlation value of this magnitude.
import numpy as np
from scipy.stats import pearson
pearson(data.loc[:, ‘Pclass’], data.Survived)
Select Features¶
All of the features we find in the dataset might not be useful in building a machine learning model to make the necessary prediction. Using some of the features might even make the predictions worse.

Often in data science we have hundreds or even millions of features and we want a way to create a model that only includes the most important features. This has three benefits.
- It reduces the variance of the model, and therefore overfitting.
- It reduces the complexity of a model and makes it easier to interpret.
- It improves the accuracy of a model if the right subset is chosen.
- Finally, it reduces the computational cost (and time) of training a model.
So, an alternative way to reduce the complexity of the model and avoid overfitting is dimensionality reduction via feature selection, which is especially useful for unregularized models. There are two main categories of dimensionality reduction techniques: feature selection and feature extraction. Using feature selection, we select a subset of the original features. In feature extraction, we derive information from the feature set to construct a new feature subspace.
Exist various methodologies and techniques that you can use to subset your feature space and help your models perform better and efficiently. So, let’s get started.
First check for any correlations between features¶
Correlation is a statistical term which in common usage refers to how close two features are to having a linear relationship with each other. The Pearson’s correlation which measures linear correlation between two features, the resulting value lies in [-1;1], with -1 meaning perfect negative correlation (as one feature increases, the other decreases), +1 meaning perfect positive correlation and 0 meaning no linear correlation between the two features.
Features with high correlation are more linearly dependent and hence have almost the same effect on the dependent variable. So, when two features have high correlation, we can drop one of the two features.
There are five assumptions that are made with respect to Pearson’s correlation:
- The feature must be either interval or ratio measurements.
- The variables must be approximately normally distributed.
- There is a linear relationship between the two variables.
- Outliers are either kept to a minimum or are removed entirely
- There is homoscedasticity of the data. Homoscedasticity basically means that the variances along the line of best fit remain similar as you move along the line.
One obvious drawback of Pearson correlation as a feature ranking mechanism is that it is only sensitive to a linear relationship. If the relation is non-linear, Pearson correlation can be close to zero even if there is a 1-1 correspondence between the two variables. For example, correlation between x and x2 is zero, when x is centered on 0.
Furthermore, relying only on the correlation value on interpreting the relationship of two variables can be highly misleading, so it is always worth plotting the data as we did on the EDA phase.
The following guidelines interpreting Pearson’s correlation coefficient (r):
| Strength of Association | r Positive | r Negative |
|---|---|---|
| Small | .1 to .3 | -0.1 to -0.3 |
| Medium | .3 to .5 | -0.3 to -0.5 |
| Large | .5 to 1.0 | -0.5 to -1.0 |
The correlation matrix is identical to a covariance matrix computed from standardized data. The correlation matrix is a square matrix that contains the Pearson product-moment correlation coefficients (often abbreviated as Pearson’s r), which measure the linear dependence between pairs of features. Pearson’s correlation coefficient can simply be calculated as the covariance between two features x and y (numerator) divided by the product of their standard deviations (denominator):
The covariance between standardized features is in fact equal to their linear correlation coefficient.
Let’s check what are the highest correlations with survived, I will now create a correlation matrix to quantify the linear relationship between the features. To do this I use NumPy’s corrcoef and seaborn’s heatmap function to plot the correlation matrix array as a heat map.
corr = data.loc[:, 'Survived':].corr()
top_corr_cols = corr[abs(corr.Survived)>=0.06].Survived.sort_values(ascending=False).keys()
top_corr = corr.loc[top_corr_cols, top_corr_cols]
dropSelf = np.zeros_like(top_corr)
dropSelf[np.triu_indices_from(dropSelf)] = True
plt.figure(figsize=(15, 15))
sns.heatmap(top_corr, cmap=sns.diverging_palette(220, 10, as_cmap=True), annot=True, fmt=".2f", mask=dropSelf)
sns.set(font_scale=0.8)
plt.show()

Let’s see we have more surnames between 0.05 and 0.06 of correlation wit Survived.
display(corr[(abs(corr.Survived)>=0.05) & (abs(corr.Survived)<0.06)].Survived.sort_values(ascending=False).keys())
del corr, dropSelf, top_corr
Drop the features with highest correlations to other Features:¶
Colinearity is the state where two variables are highly correlated and contain similar information about the variance within a given dataset. And as you see above, it is easy to find highest collinearities (Personal_Titles_Mrs, Personal_Titles_Mr and Fare.
You should always be concerned about the collinearity, regardless of the model/method being linear or not, or the main task being prediction or classification.
Assume a number of linearly correlated covariates/features present in the data set and Random Forest as the method. Obviously, random selection per node may pick only (or mostly) collinear features which may/will result in a poor split, and this can happen repeatedly, thus negatively affecting the performance.
Now, the collinear features may be less informative of the outcome than the other (non-collinear) features and as such they should be considered for elimination from the feature set anyway. However, assume that the features are ranked high in the ‘feature importance’ list produced by RF. As such they would be kept in the data set unnecessarily increasing the dimensionality. So, in practice, I’d always, as an exploratory step (out of many related) check the pairwise association of the features, including linear correlation.
Identify and treat multicollinearity:¶
Multicollinearity is more troublesome to detect because it emerges when three or more variables, which are highly correlated, are included within a model, leading to unreliable and unstable estimates of regression coefficients. To make matters worst multicollinearity can emerge even when isolated pairs of variables are not collinear.
To identify, we need start with the coefficient of determination, r2, is the square of the Pearson correlation coefficient r. The coefficient of determination, with respect to correlation, is the proportion of the variance that is shared by both variables. It gives a measure of the amount of variation that can be explained by the model (the correlation is the model). It is sometimes expressed as a percentage (e.g., 36% instead of 0.36) when we discuss the proportion of variance explained by the correlation. However, you should not write r2 = 36%, or any other percentage. You should write it as a proportion (e.g., r2 = 0.36).
Already the Variance Inflation Factor (VIF) is a measure of collinearity among predictor variables within a multiple regression. It is may be calculated for each predictor by doing a linear regression of that predictor on all the other predictors, and then obtaining the R2 from that regression. It is calculated by taking the the ratio of the variance of all a given model’s betas divide by the variance of a single beta if it were fit alone [1/(1-R2)]. Thus, a VIF of 1.8 tells us that the variance (the square of the standard error) of a particular coefficient is 80% larger than it would be if that predictor was completely uncorrelated with all the other predictors. The VIF has a lower bound of 1 but no upper bound. Authorities differ on how high the VIF has to be to constitute a problem (e.g.: 2.50 (R2 equal to 0.6), sometimes 5 (R2 equal to .8), or greater than 10 (R2 equal to 0.9) and so on).
But there are several situations in which multicollinearity can be safely ignored:
- Interaction terms and higher-order terms (e.g., squared and cubed predictors) are correlated with main effect terms because they include the main effects terms. Ops! Sometimes we use polynomials to solve problems, indeed! But keep calm, in these cases, standardizing the predictors can removed the multicollinearity.
- Indicator, like dummy or one-hot-encode, that represent a categorical variable with three or more categories. If the proportion of cases in the reference category is small, the indicator will necessarily have high VIF’s, even if the categorical is not associated with other variables in the regression model. But, you need check if some dummy is collinear or has multicollinearity with other features outside of their dummies.
- *Control feature if the feature of interest do not have high VIF’s. Here’s the thing about multicollinearity: it’s only a problem for the features that are collinear. It increases the standard errors of their coefficients, and it may make those coefficients unstable in several ways. But so long as the collinear feature are only used as control feature, and they are not collinear with your feature of interest, there’s no problem. The coefficients of the features of interest are not affected, and the performance of the control feature as controls is not impaired.
So, generally, we could run the same model twice, once with severe multicollinearity and once with moderate multicollinearity. This provides a great head-to-head comparison and it reveals the classic effects of multicollinearity. However, when standardizing your predictors doesn’t work, you can try other solutions such as:
- removing highly correlated predictors
- linearly combining predictors, such as adding them together
- running entirely different analyses, such as partial least squares regression or principal components analysis
When considering a solution, keep in mind that all remedies have potential drawbacks. If you can live with less precise coefficient estimates, or a model that has a high R-squared but few significant predictors, doing nothing can be the correct decision because it won’t impact the fit.
Given the potential for correlation among the predictors, we’ll have display the variance inflation factors (VIF), which indicate the extent to which multicollinearity is present in a regression analysis. Hence such variables need to be removed from the model. Deleting one variable at a time and then again checking the VIF for the model is the best way to do this.
So, I start the analysis removed the 3 features with he highest collinearities and the surnames different from my control surname_Alone and correlation with survived less then 0.05, and run VIF.
#Step 1: Remove the higest correlations and run a multiple regression
cols = [ 'family',
'non_relatives',
'surname_Alone',
'surname_Baclini',
'surname_Carter',
'surname_Richards',
'surname_Harper', 'surname_Beckwith', 'surname_Goldenberg',
'surname_Moor', 'surname_Chambers', 'surname_Hamalainen',
'surname_Dick', 'surname_Taylor', 'surname_Doling', 'surname_Gordon',
'surname_Beane', 'surname_Hippach', 'surname_Bishop',
'surname_Mellinger', 'surname_Yarred',
'Pclass',
'Age',
'SibSp',
'Parch',
#'Fare',
'qtd_same_ticket_bin',
'passenger_fare',
#'SibSp_bin',
#'Parch_bin',
'distinction_in_name',
'Cabin_Number',
'sons',
'parents',
'relatives',
'companions',
'alone',
'Without_Age',
'Age_bin_custom_label',
'genre',
'Cabin_Letter_A',
'Cabin_Letter_B',
'Cabin_Letter_C',
'Cabin_Letter_D',
'Cabin_Letter_E',
'Cabin_Letter_F',
'Cabin_Letter_G',
'Personal_Titles_Kid',
'Personal_Titles_Miss',
#'Personal_Titles_Mr',
#'Personal_Titles_Mrs',
'Personal_Titles_Royalty',
'Personal_Titles_Technical',
'Embarked_C',
'Embarked_Q',
'Embarked_S',
'distinction_in_tikect_High',
'distinction_in_tikect_Low',
'distinction_in_tikect_Others',
'distinction_in_tikect_PC'
]
y_train = data.Survived[data.Survived>=0]
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
features = "+".join(cols)
df2 = pd.concat([y_train, df], axis=1)
# get y and X dataframes based on this regression:
y, X = dmatrices('Survived ~' + features, data = df2, return_type='dataframe')
#Step 2: Calculate VIF Factors
# For each X, calculate VIF and save in dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#Step 3: Inspect VIF Factors
display(vif.sort_values('VIF Factor'))
From the results, I conclude that can safe maintain the dummies of Embarked, but need work in the remaining features where’s the VIF stated as inf. You can see that surname Alone has a VIF of 2.2. We’re going to treat it as our baseline and exclude it from our fit. This is done to prevent multicollinearity, or the dummy variable trap caused by including a dummy variable for every single category. let’s try remove the dummy alone, that is pretty similar, and check if it solves the other dummies from its category:
#Step 1: Remove one feature with VIF on Inf from the same category and run a multiple regression
cols.remove('alone')
y_train = data.Survived[data.Survived>=0]
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
features = "+".join(cols)
df2 = pd.concat([y_train, df], axis=1)
# get y and X dataframes based on this regression:
y, X = dmatrices('Survived ~' + features, data = df2, return_type='dataframe')
#Step 2: Calculate VIF Factors
# For each X, calculate VIF and save in dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#Step 3: Inspect VIF Factors
display(vif.sort_values('VIF Factor'))
To solve Cabin Letter, we can try remove only the lowest frequency ‘A’, and see if we can accept the VIF’s of others Cabins:
#Step 1: Remove one feature with VIF on Inf from the same category and run a multiple regression
cols.remove('Cabin_Letter_A')
y_train = data.Survived[data.Survived>=0]
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
features = "+".join(cols)
df2 = pd.concat([y_train, df], axis=1)
# get y and X dataframes based on this regression:
y, X = dmatrices('Survived ~' + features, data = df2, return_type='dataframe')
#Step 2: Calculate VIF Factors
# For each X, calculate VIF and save in dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#Step 3: Inspect VIF Factors
display(vif.sort_values('VIF Factor'))
Now our focus is on distinct in name, since “High” has less observations, let’s try dropped it and drop the bins of Parch and SibSp.
cols.remove('distinction_in_tikect_High')
y_train = data.Survived[data.Survived>=0]
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
features = "+".join(cols)
df2 = pd.concat([y_train, df], axis=1)
# get y and X dataframes based on this regression:
y, X = dmatrices('Survived ~' + features, data = df2, return_type='dataframe')
#Step 2: Calculate VIF Factors
# For each X, calculate VIF and save in dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#Step 3: Inspect VIF Factors
display(vif.sort_values('VIF Factor'))
As we can see, we now have to remove one between family, parch and SibSp. Note that non_relatives qtd_same_ticket_bin are already with relatively acceptable VIF’s. The first is directly calculated from the family and the second is very close as we have seen. So let’s discard the family.
cols.remove('family')
y_train = data.Survived[data.Survived>=0]
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
features = "+".join(cols)
df2 = pd.concat([y_train, df], axis=1)
# get y and X dataframes based on this regression:
y, X = dmatrices('Survived ~' + features, data = df2, return_type='dataframe')
#Step 2: Calculate VIF Factors
# For each X, calculate VIF and save in dataframe
vif = pd.DataFrame()
vif["VIF Factor"] = [variance_inflation_factor(X.values, i) for i in range(X.shape[1])]
vif["features"] = X.columns
#Step 3: Inspect VIF Factors
display(vif.sort_values('VIF Factor'))
Yea, we can accept, and we can proceed to the next step.
Feature Selection by Filter Methods¶
Filter methods use statistical methods for evaluation of a subset of features, they are generally used as a preprocessing step. These methods are also known as univariate feature selection, they examines each feature individually to determine the strength of the relationship of the feature with the dependent variable. These methods are simple to run and understand and are in general particularly good for gaining a better understanding of data, but not necessarily for optimizing the feature set for better generalization.
So, the features are selected on the basis of their scores in various statistical tests for their correlation with the outcome variable. The correlation is a subjective term here. For basic guidance, you can refer to the following table for defining correlation co-efficients.
| Feature/Response | Continuous | Categorical |
|---|---|---|
| Continuous | Pearson’s Correlation | LDA |
| Categorical | Anova | Chi-Square |
One thing that should be kept in mind is that filter methods do not remove multicollinearity. So, you must deal with multicollinearity of features as well before training models for your data.
There are lot of different options for univariate selection. Some examples are:
- Model Based Ranking
- Mutual information and maximal information coefficient (MIC).
I did not approach the latter, because there has been some critique about MIC’s statistical power, i.e. the ability to reject the null hypothesis when the null hypothesis is false. This may or may not be a concern, depending on the particular dataset and its noisiness. If you have interest on this, in python, MIC is available in the minepy library.
Feature Selection by Model based ranking¶
We can use an arbitrary machine learning method to build a predictive model for the response variable using each individual feature, and measure the performance of each model.
In fact, this is already put to use with Pearson’s correlation coefficient, since it is equivalent to standardized regression coefficient that is used for prediction in linear regression. But this method it is not good to select features with non-linear relation to dependent variable. For this, there are a number of alternatives, for example tree based methods (decision trees, random forest), linear model with basis expansion etc. Tree based methods are probably among the easiest to apply, since they can model non-linear relations well and don’t require much tuning. The main thing to avoid is overfitting, so the depth of tree(s) should be relatively small, and cross-validation should be applied.
rf = RandomForestClassifier(n_estimators=20, max_depth=4, random_state=101)
scores = []
for i in range(df.shape[1]):
score = cross_val_score(rf, df.iloc[:, i:i+1], y_train, scoring="accuracy", cv=10)
scores.append((round(np.mean(score), 3), cols[i]))
MBR = pd.DataFrame(sorted(scores, reverse=True), columns=['Score', 'Feature'])
g = MBR.iloc[:15, :].plot(x='Feature', kind='barh', figsize=(20,10), fontsize=12, grid=True)
plt.show()
MBR = MBR.iloc[:15, 1]

Feature Selection by SelectKBest:¶
On scikit-learn we find variety of implementation oriented to classifications tasks to select features according to the k highest scores, see below some of that:
- f_classif compute the ANOVA F-value for the provided sample.
- chi2 compute chi-squared stats between each non-negative feature and class.
- mutual_info_classif estimate mutual information for a discrete target variable.
The methods based on F-test estimate the degree of linear dependency between two random variables. On the other hand, mutual information methods can capture any kind of statistical dependency, but being nonparametric, they require more samples for accurate estimation.
Other important point is if you use sparse data, for example if we continue consider hot-encode of surnames, chi2 and mutual_info_classif will deal with the data without making it dense.
Let’s see the SelectKBest of f_classif and chi2 for our data:
cols = pd.Index(cols)
skb = SelectKBest(score_func=f_classif, k=10)
skb.fit(df, y_train)
select_features_kbest = skb.get_support()
feature_f_clas = cols[select_features_kbest]
feature_f_clas_scores = [(item, score) for item, score in zip(cols, skb.scores_)]
print('Total features slected by f_classif Statistical Methods',len(feature_f_clas))
fig = plt.figure(figsize=(20,7))
f1 = fig.add_subplot(121)
g = pd.DataFrame(sorted(feature_f_clas_scores, key=lambda x: -x[1])[:len(feature_f_clas)], columns=['Feature','F-Calss Score']).\
plot(x='Feature', kind='barh', title= 'F Class Score', fontsize=18, ax=f1, grid=True)
scale = MinMaxScaler()
df2 = scale.fit_transform(data.loc[data.Survived>=0, cols])
skb = SelectKBest(score_func=chi2, k=10)
skb.fit(df2, y_train)
select_features_kbest = skb.get_support()
feature_chi2 = cols[select_features_kbest]
feature_chi2_scores = [(item, score) for item, score in zip(cols, skb.scores_)]
print('Total features slected by chi2 Statistical Methods',len(feature_chi2))
f2 = fig.add_subplot(122)
g = pd.DataFrame(sorted(feature_chi2_scores, key=lambda x: -x[1])[:len(feature_chi2)], columns=['Feature','Chi2 Score']).\
plot(x='Feature', kind='barh', title= 'Chi2 Score', fontsize=18, ax=f2, grid=True)
SMcols = set(feature_f_clas).union(set(feature_chi2))
print("Extra features select by f_class:\n", set(feature_f_clas).difference(set(feature_chi2)), '\n')
print("Extra features select by chi2:\n", set(feature_chi2).difference(set(feature_f_clas)), '\n')
print("Intersection features select by f_class and chi2:\n",set(feature_f_clas).intersection(set(feature_chi2)), '\n')
print('Total number of features selected:', len(SMcols))
print(SMcols)
plt.tight_layout(); plt.show()

Wrapper Methods¶
In wrapper methods, we try to use a subset of features and train a model using them. Based on the inferences that we draw from the previous model, we decide to add or remove features from your subset. The problem is essentially reduced to a search problem.
The two main disadvantages of these methods are :
- The increasing overfitting risk when the number of observations is insufficient.
- These methods are usually computationally very expensive.
Backward Elimination¶
In backward elimination, we start with all the features and removes the least significant feature at each iteration which improves the performance of the model. We repeat this until no improvement is observed on removal of features.
We will see below row implementation of backward elimination, one to select by P-values and other based on the accuracy of a model the we submitted to it.
Backward Elimination By P-values¶
The P-value, or probability value, or asymptotic significance, is a probability value for a given statistical model that, if the null hypothesis is true, a set of statistical observations more commonly known as the statistical summary is greater than or equal in magnitude to the observed results.
The null hypothesis is a general statement that there is no relationship between two measured phenomena.
For example, if the correlation is very small and furthermore, the p-value is high meaning that it is very likely to observe such correlation on a dataset of this size purely by chance.
But you need to be careful how you interpret the statistical significance of a correlation. If your correlation coefficient has been determined to be statistically significant this does not mean that you have a strong association. It simply tests the null hypothesis that there is no relationship. By rejecting the null hypothesis, you accept the alternative hypothesis that states that there is a relationship, but with no information about the strength of the relationship or its importance.
Since removal of different features from the dataset will have different effects on the p-value for the dataset, we can remove different features and measure the p-value in each case. These measured p-values can be used to decide whether to keep a feature or not.
Next we make the test of a logit regression to check the result and select features based on its the P-value:
logit_model=sm.Logit(y_train,df)
result=logit_model.fit(method='bfgs', maxiter=2000)
print(result.summary())
As expect, P-values of dummies is high. Like before, I excluded one by one of the features with the highest P-value and run again until get only P-values below to 0.1, but here I use a backward elimination process.
pv_cols = cols.values
def backwardElimination(x, Y, sl, columns):
numVars = x.shape[1]
for i in range(0, numVars):
regressor = sm.Logit(Y, x).fit(method='bfgs', maxiter=2000, disp=False)
maxVar = max(regressor.pvalues) #.astype(float)
if maxVar > sl:
for j in range(0, numVars - i):
if (regressor.pvalues[j].astype(float) == maxVar):
columns = np.delete(columns, j)
x = x.loc[:, columns]
print(regressor.summary())
print('\nSelect {:d} features from {:d} by best p-values.'.format(len(columns), len(pv_cols)))
print('The max p-value from the features selecte is {:.3f}.'.format(maxVar))
# odds ratios and 95% CI
conf = np.exp(regressor.conf_int())
conf['Odds Ratios'] = np.exp(regressor.params)
conf.columns = ['2.5%', '97.5%', 'Odds Ratios']
display(conf)
return columns, regressor
SL = 0.1
df2 = scale.fit_transform(data.loc[data.Survived>=0, pv_cols])
df2 = pd.DataFrame(df2, columns = pv_cols)
pv_cols, Logit = backwardElimination(df2, y_train, SL, pv_cols)
From the results, we can highlight:
-
we’re very confident about some relationship between the probability of being survived:
- there is an inverse relationship with class, Age and genre of the passenger.
- there is an positive relationship, from greater to low, with non relatives, Kids, passenger fare and distinction in name of the passenger.
-
From the coefficient:
- Non relatives, we confirm that fellows or companions of families had better chances to survived.
- As we saw in the EDA, passengers who embarked on S had a higher fatality rate.
- The model is only able to translate a single straight line by variable, obviously pondered by the others. Then he points out that the greater the number of passengers with the same ticket, the greater the likelihood of death. As seen through the ticket EDA, this is partly true, however, this coefficient does not adequately capture the fact that the chances of survival increase from 1 to 3 passengers with the same ticket. As you can see above, the model balances this through the variables of family relationships. However, this is a good example of why you should not ignore the EDA phase, and above all do not rely on a conclusion based on a single fact or point of view. Remember, models are not full truths, and possess precision, confident and accuracy!
Take the exponential of each of the coefficients to generate the odds ratios. This tells you how a 1 unit increase or decrease in a variable affects the odds of being survived. For example, we can expect the odds of being survived to decrease by about 69.5% if the passenger embarked on S. Go back to the embarked EDA and see that this hits the stacked bar chart.
You must be wondering, after all, this model has how much of accuracy?
Although we did not do cross validation or even split, let’s take a look, redeem the probabilities generated by it and take advantage to see how we can plot the results of models that return probabilities, so we can refine our perception much more than simply evaluate p-value, coefficients, accuracy, etc.
pred = Logit.predict(df2[pv_cols])
train = data[data.Survived>=0]
train['proba'] = pred
train['Survived'] = y_train
y_pred = pred.apply(lambda x: 1 if x > 0.5 else 0)
print('Accurancy: {0:2.2%}'.format(accuracy_score(y_true=y_train, y_pred=y_pred)))
def plot_proba(continous, predict, discret, data):
grouped = pd.pivot_table(data, values=[predict], index=[continous, discret], aggfunc=np.mean)
colors = 'rbgyrbgy'
for col in data[discret].unique():
plt_data = grouped.ix[grouped.index.get_level_values(1)==col]
plt.plot(plt_data.index.get_level_values(0), plt_data[predict], color=colors[int(col)])
plt.xlabel(continous)
plt.ylabel("Probabilities")
plt.legend(np.sort(data[discret].unique()), loc='upper left', title=discret)
plt.title("Probabilities with " + continous + " and " + discret)
fig = plt.figure(figsize=(20, 10))
ax = fig.add_subplot(231)
plot_proba('non_relatives', 'Survived', 'Pclass', train)
ax = fig.add_subplot(232)
plot_proba('non_relatives', 'Survived', 'genre', train)
ax = fig.add_subplot(233)
plot_proba('non_relatives', 'Survived', 'qtd_same_ticket_bin', train)
ax = fig.add_subplot(234)
plot_proba('qtd_same_ticket_bin', 'Survived', 'distinction_in_name', train)
ax = fig.add_subplot(235)
plot_proba('qtd_same_ticket_bin', 'Survived', 'Embarked_S', train)
ax = fig.add_subplot(235)
plot_proba('qtd_same_ticket_bin', 'Survived', 'Embarked_S', train)
ax = fig.add_subplot(236)
plot_proba('qtd_same_ticket_bin', 'Survived', 'parents', train)
plt.show()

Backward Elimination By Accuracy – A Sequential Backward Selection¶
Sequential feature selection algorithms are a family of greedy search algorithms that are used to reduce an initial d-dimensional feature space to a k-dimensional feature subspace where k < d. The motivation behind feature selection algorithms is to automatically select a subset of features that are most relevant to the problem to improve computational efficiency or reduce the generalization error of the model by removing irrelevant features or noise, which can be useful for algorithms that don’t
support regularization.
Greedy algorithms make locally optimal choices at each stage of a combinatorial search problem and generally yield a suboptimal solution to the problem in contrast to exhaustive search algorithms, which evaluate all possible combinations and are guaranteed to find the optimal solution. However, in practice, an exhaustive search is often computationally not feasible, whereas greedy algorithms allow for a less complex, computationally more efficient solution.
SBS aims to reduce the dimensionality of the initial feature subspace with a minimum decay in performance of the classifier to improve upon computational efficiency. In certain cases, SBS can even improve the predictive power of the model if a model suffers from overfitting.
SBS sequentially removes features from the full feature subset until the new feature subspace contains the desired number of features. In order to determine which feature is to be removed at each stage, we need to define criterion function J that we want to minimize. The criterion calculated by the criterion function can simply be the difference in performance of the classifier after and before the removal of a particular feature. Then the feature to be removed at each stage can simply be defined as the feature that maximizes this criterion.
From interactive executions, I already know that I need remove the surnames with less than 0.06 of correlation.
So, let’s see a example of SBS in our data,
class SBS():
def __init__(self, estimator, k_features, scoring=accuracy_score, test_size=0.25, random_state=101):
self.scoring = scoring
self.estimator = clone(estimator)
self.k_features = k_features
self.test_size = test_size
self.random_state = random_state
def fit(self, X, y):
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=self.test_size, random_state=self.random_state)
dim = X_train.shape[1]
self.indices_ = list(range(dim))
self.subsets_ = [self.indices_]
score = self._calc_score(X_train, y_train, X_test, y_test, self.indices_)
self.scores_ = [score]
while dim > self.k_features:
scores = []
subsets = []
for p in combinations(self.indices_, r=dim-1):
score = self._calc_score(X_train, y_train, X_test, y_test, list(p))
scores.append(score)
subsets.append(list(p))
best = np.argmax(scores)
self.indices_ = subsets[best]
self.subsets_.append(self.indices_)
dim -= 1
self.scores_.append(scores[best])
self.k_score_ = self.scores_[-1]
return self
def transform(self, X):
return X.iloc[:, self.indices_]
def _calc_score(self, X_train, y_train, X_test, y_test, indices):
self.estimator.fit(X_train.iloc[:, indices], y_train)
y_pred = self.estimator.predict(X_test.iloc[:, indices])
score = self.scoring(y_test, y_pred)
return score
knn = KNeighborsClassifier(n_neighbors=3)
sbs = SBS(knn, k_features=1)
df2 = df.drop(['surname_Harper', 'surname_Beckwith', 'surname_Goldenberg',
'surname_Moor', 'surname_Chambers', 'surname_Hamalainen',
'surname_Dick', 'surname_Taylor', 'surname_Doling', 'surname_Gordon',
'surname_Beane', 'surname_Hippach', 'surname_Bishop',
'surname_Mellinger', 'surname_Yarred'], axis = 1)
sbs.fit(df2, y_train)
print('Best Score:',max(sbs.scores_))
k_feat = [len(k) for k in sbs.subsets_]
fig = plt.figure(figsize=(10,5))
plt.plot(k_feat, sbs.scores_, marker='o')
#plt.ylim([0.7, max(sbs.scores_)+0.01])
plt.xlim([1, len(sbs.subsets_)])
plt.xticks(np.arange(1, len(sbs.subsets_)+1))
plt.ylabel('Accuracy')
plt.xlabel('Number of features')
plt.grid(b=1)
plt.show()
print('First best accuracy with:\n',list(df.columns[sbs.subsets_[np.argmax(sbs.scores_)]]))
SBS = list(df.columns[list(sbs.subsets_[max(np.arange(0, len(sbs.scores_))[(sbs.scores_==max(sbs.scores_))])])])
print('\nBest accuracy with {0:2d} features:\n{1:}'.format(len(SBS), SBS))

Select Features by Recursive Feature Elimination¶
The goal of Recursive Feature Elimination (RFE) is to select features by recursively considering smaller and smaller sets of features.
RFE is based on the idea to repeatedly construct a model and choose either the best or worst performing feature, setting the feature aside and then repeating the process with the rest of the features. This process is applied until all features in the dataset are exhausted.
Other option is sequential Feature Selector (SFS) from mlxtend, a separate Python library that is designed to work well with scikit-learn, also provides a S that works a bit differently.
RFE is computationally less complex using the feature’s weight coefficients (e.g., linear models) or feature importances (tree-based algorithms) to eliminate features recursively, whereas SFSs eliminate (or add) features based on a user-defined classifier/regression performance metric.
from sklearn.feature_selection import RFE
lr = LogisticRegression()
rfe = RFE(estimator=lr, step=1)
rfe.fit(df, y_train)
FRFE = cols[rfe.ranking_==1]
print('\nFeatures selected:\n',FRFE)
print('\n Total Features selected:',len(FRFE))
Select Features by Embedded Methods¶
In addition to the return of the performance itself, some models has in their internal process some step to features select that best fit their proposal, and returns the features importance too. Thus, they provide two straightforward methods for feature selection and combine the qualities’ of filter and wrapper methods.
Some of the most popular examples of these methods are LASSO, RIDGE, SVM, Regularized trees, Memetic algorithm, and Random multinomial logit.
In the case of Random Forest, some other models base on trees, we have two basic approaches implemented in the packages:
- Gini/Entropy Importance or Mean Decrease in Impurity (MDI)
- Permutation Importance or Mean Decrease in Accuracy
- Permutation with Shadow Features
- Gradient Boosting
Others models has concerns om multicollinearity problem and adding additional constraints or penalty to regularize. When there are multiple correlated features, as is the case with very many real life datasets, the model becomes unstable, meaning that small changes in the data can cause large changes in the model, making model interpretation very difficult on the regularization terms.
This applies to regression models like LASSO and RIDGE. In classifier cases, you can use SGDClassifier where you can set the loss parameter to ‘log’ for Logistic Regression or ‘hinge’ for SVM. In SGDClassifier you can set the penalty to either of ‘l1’, ‘l2’ or ‘elasticnet’ which is a combination of both.
Let’s start with more details and examples:
Feature Selection by Mean Decrease Impurity¶
There are a two things to keep in mind when using the impurity based ranking:
- Feature selection based on impurity reduction is biased towards preferring variables with more categories.
- It can lead to the incorrect conclusion that one of the features is a strong predictor while the others in the same group are unimportant, while actually they are very close in terms of their relationship with the independent variable.
The second one refers to when the dataset has two or more correlated features, then from the point of view of the model, any of these correlated features can be used as the predictor, with no concrete preference of one over the others. But once one of them is used, the importance of others is significantly reduced since effectively the impurity they can remove is already removed by the first feature. As a consequence, they will have a lower reported importance. This is not an issue when we want to use feature selection to reduce overfitting, since it makes sense to remove features that are mostly duplicated by other features. But when interpreting the data. The effect of this phenomenon is somewhat reduced thanks to random selection of features at each node creation, but in general the effect is not removed completely.
The Random Forests is one of them, the reason is because the tree-based strategies used by random forests naturally ranks by how well they improve the purity of the node. This mean decrease in impurity over all trees, wheres for classification, it is typically either Gini impurity or information gain/entropy and for *regression it is variance. Thus when training a tree, it can be computed how much each feature decreases the weighted impurity in a tree. For a forest, the impurity decrease from each feature can be averaged and the features are ranked according to this measure.
Random forests are a popular method for feature ranking, since they are so easy to apply: in general they require very little feature engineering and parameter tuning and mean decrease impurity is exposed in most random forest libraries. But they come with their own gotchas, especially when data interpretation is concerned. With correlated features, strong features can end up with low scores and the method can be biased towards variables with many categories. As long as the gotchas are kept in mind, there really is no reason not to try them out on your data.
Them, we run a quick Random Forest to select the features most importants:
rfc = RandomForestClassifier(n_estimators=20, max_depth=4, random_state=101)
rfc.fit(df, y_train)
feature_importances = [(feature, score) for feature, score in zip(cols, rfc.feature_importances_)]
MDI = cols[rfc.feature_importances_>0.010]
print('Total features slected by Random Forest:',len(MDI))
g = pd.DataFrame(sorted(feature_importances, key=lambda x: -x[1])[:len(MDI)], columns=['Feature','Importance']).\
plot(x='Feature', kind='barh', figsize=(20,7), fontsize=18, grid=True)
plt.show()

Feature Selection by Mean Decrease Accuracy¶
The general idea is to permute the values of each feature and measure how much the permutation decreases the accuracy of the model. Clearly, for unimportant feature, the permutation should have little to no effect on model accuracy, while permuting important feature should significantly decrease it.
This method is not directly exposed in sklearn, but it is straightforward to implement it. Start record a baseline accuracy (classifier) or R2 score (regressor) by passing a validation set or the out-of-bag (OOB) samples through the random forest. Permute the column values of a single predictor feature and then pass all test samples back through the random forest and recompute the accuracy or R2. The importance of that feature is the difference between the baseline and the drop in overall accuracy or R2 caused by permuting the column. The permutation mechanism is much more computationally expensive than the mean decrease in impurity mechanism, but the results are more reliable.
The rfpimp package in the src dir provided it For Random Forest, let’s see:
X_train, X_test, y, y_test = train_test_split(df, y_train , test_size=0.20, random_state=101)
# Add column of random numbers
X_train['random'] = np.random.random(size=len(X_train))
X_test['random'] = np.random.random(size=len(X_test))
rf = RandomForestClassifier(n_estimators=100, min_samples_leaf=5, n_jobs=-1, oob_score=True, random_state=101)
rf.fit(X_train, y)
imp = importances(rf, X_test, y_test, n_samples=-1) # permutation
MDA = imp[imp!=0].dropna().index
if 'random' in MDA:
MDA = MDA.drop('random')
print('%d features are selected.' % len(MDA))
plot_importances(imp[imp!=0].dropna(), figsize=(20,7))

Feature Selection by Permutation with Shadow Features¶
Boruta randomly permutes variables like Permutation Importance does, but performs on all variables at the same time and concatenates the shuffled features with the original ones. The concatenated result is used to fit the model.
Daniel Homola, who also wrote the Python version of Boruta, BorutaPy, gave an wonderful overview of the Boruta algorithm in his blog post
“The shuffled features (a.k.a. shadow features) are basically noises with identical marginal distribution w.r.t the original feature. We count the times a variable performs better than the ‘best’ noise and calculate the confidence towards it being better than noise (the p-value) or not. Features which are confidently better are marked ‘confirmed’, and those which are confidently on par with noises are marked ‘rejected’. Then we remove those marked features and repeat the process until all features are marked or a certain number of iteration is reached.”
Although Boruta is a feature selection algorithm, we can use the order of confirmation/rejection as a way to rank the importance of features.
# NOTE BorutaPy accepts numpy arrays only, hence the .values attribute
X = df.values
y = y_train.values.ravel()
# define random forest classifier, with utilising all cores and
# sampling in proportion to y labels
#rf = RandomForestClassifier(n_estimators=10, min_samples_leaf=5, n_jobs=-1, oob_score=True, random_state=101)
rf = ExtraTreesClassifier(n_estimators=100, max_depth=4, n_jobs=-1, oob_score=True, bootstrap=True, random_state=101)
# define Boruta feature selection method
feat_selector = BorutaPy(rf, n_estimators='auto', verbose=0, random_state=101)
# find all relevant features - 5 features should be selected
feat_selector.fit(X, y)
shadow = cols[feat_selector.support_]
# check selected features - first 5 features are selected
print('Features selected:',shadow)
# call transform() on X to filter it down to selected features
print('Data transformaded has %d features' % feat_selector.n_features_) #feat_selector.transform(X).shape[1])
print('Check the selector ranking:')
display(pd.concat([pd.DataFrame(cols, columns=['Columns']),
pd.DataFrame(feat_selector.ranking_, columns=['Rank'])], axis=1).sort_values(by=['Rank']))
Feature Selection by Gradient Boosting¶
The LightGBM model the importance is calculated from, if ‘split’, result contains numbers of times the feature is used in a model, if ‘gain’, result contains total gains of splits which use the feature.
On the XGBoost model the importance is calculated by:
- ‘weight’: the number of times a feature is used to split the data across all trees.
- ‘gain’: the average gain across all splits the feature is used in.
- ‘cover’: the average coverage across all splits the feature is used in.
- ‘total_gain’: the total gain across all splits the feature is used in.
- ‘total_cover’: the total coverage across all splits the feature is used in.
First measure is split-based and is very similar with the one given by for Gini Importance. But it doesn’t take the number of samples into account.
The second measure is gain-based. It’s basically the same as the Gini Importance implemented in R packages and in scikit-learn with Gini impurity replaced by the objective used by the gradient boosting model.
The cover, implemented exclusively in XGBoost, is counting the number of samples affected by the splits based on a feature.
get_score(fmap=”, importance_type=’weight’)
Get feature importance of each feature. Importance type can be defined as:
The default measure of both XGBoost and LightGBM is the split-based one. I think this measure will be problematic if there are one or two feature with strong signals and a few features with weak signals. The model will exploit the strong features in the first few trees and use the rest of the features to improve on the residuals. The strong features will look not as important as they actually are. While setting lower learning rate and early stopping should alleviate the problem, also checking gain-based measure may be a good idea.
Note that these measures are purely calculated using training data, so there’s a chance that a split creates no improvement on the objective in the holdout set. This problem is more severe than in the random forest since gradient boosting models are more prone to over-fitting.
Feature importance scores can be used for feature selection in scikit-learn.
This is done using the SelectFromModel class that takes a model and can transform a dataset into a subset with selected features.
This class can take a previous trained model, such as one trained on the entire training dataset. It can then use a threshold to decide which features to select. This threshold is used when you call the transform() method on the SelectFromModel instance to consistently select the same features on the training dataset and the test dataset.
warnings.filterwarnings(action='ignore', category=DeprecationWarning)
# split data into train and test sets
X_train, X_test, y, y_test = train_test_split(df, y_train, test_size=0.30, random_state=101)
# fit model on all training data
model = XGBClassifier(importance_type='gain', scale_pos_weight=((len(y)-y.sum())/y.sum()))
model.fit(X_train, y)
fig=plt.figure(figsize=(20,5))
ax = fig.add_subplot(121)
g = plot_importance(model, height=0.5, ax=ax)
# Using each unique importance as a threshold
thresholds = np.sort(np.unique(model.feature_importances_)) #np.sort(model.feature_importances_[model.feature_importances_>0])
best = 0
colsbest = 31
my_model = model
threshold = 0
for thresh in thresholds:
# select features using threshold
selection = SelectFromModel(model, threshold=thresh, prefit=True)
select_X_train = selection.transform(X_train)
# train model
selection_model = XGBClassifier(importance_type='gain', scale_pos_weight=((len(y)-y.sum())/y.sum()))
selection_model.fit(select_X_train, y)
# eval model
select_X_test = selection.transform(X_test)
y_pred = selection_model.predict(select_X_test)
predictions = [round(value) for value in y_pred]
accuracy = accuracy_score(y_test, predictions)
print("Thresh={:1.3f}, n={:d}, Accuracy: {:2.2%}".format(thresh, select_X_train.shape[1], accuracy))
if (best <= accuracy):
best = accuracy
colsbest = select_X_train.shape[1]
my_model = selection_model
threshold = thresh
ax = fig.add_subplot(122)
g = plot_importance(my_model,height=0.5, ax=ax,
title='The best accuracy: {:2.2%} with {:d} features'.\
format(best, colsbest))
feature_importances = [(score, feature) for score, feature in zip(model.feature_importances_, cols)]
XGBest = pd.DataFrame(sorted(sorted(feature_importances, reverse=True)[:colsbest]), columns=['Score', 'Feature'])
g = XGBest.plot(x='Feature', kind='barh', figsize=(20,7), fontsize=14, grid= True,
title='Original feature importance from selected features')
plt.tight_layout(); plt.show()
XGBestCols = XGBest.iloc[:, 1].tolist()


Feature Selection by Regularized Models¶
Regularization is a method for adding additional constraints or penalty to a model, with the goal of preventing overfitting and improving generalization. Instead of minimizing a loss function E(X,Y), the loss function to minimize becomes E(X,Y)+α∥w∥, where w is the vector of model coefficients, ∥⋅∥ is typically L1 or L2 norm and α is a tunable free parameter, specifying the amount of regularization (so α=0 implies an unregularized model). The two widely used regularization methods are L1 and L2 regularization, also called lasso and ridge.
Regularized models are a powerful set of tool for feature interpretation and selection. Lasso produces sparse solutions and as such is very useful selecting a strong subset of features for improving model performance. Ridge on the other hand can be used for data interpretation due to its stability and the fact that useful features tend to have non-zero coefficients. Since the relationship between the response variable and features in often non-linear, basis expansion can be used to convert features into a more suitable space, while keeping the simple linear models fully applicable.
Let’s see the SGDClassifier that have this concept implemented for classifications cases, and to address the skewness of our dataset in terms of labels we use the class_weight parameter of SGDCassifier and set it to “balanced”:
X_train, X_test, y, y_test = train_test_split(df, y_train , test_size=0.20, random_state=101)
# Add column of random numbers
X_train['random'] = np.random.random(size=len(X_train))
X_test['random'] = np.random.random(size=len(X_test))
svm = SGDClassifier(penalty='elasticnet', class_weight='balanced', n_jobs = - 1, random_state=101)
svm.fit(X_train, y)
imp = importances(svm, X_test, y_test, n_samples=-1) # permutation
RM = imp[imp!=0].dropna().index
if 'random' in RM:
RM = RM.drop('random')
print('%d features are selected.' % len(RM))
plot_importances(imp[imp!=0].dropna(), figsize=(20,7))

Combine Features Selection Methods¶
As each machine learning model benefits from one or another set of features selected, depending on its own method, and our dataset does in fact present few features, since we first removed the collinear and multilinear with the highest correlation and the highest degree of FIV that represents risk for our model, now we can union all selected features in a unique set, and check what features are elected exclusively by a unique method.
bcols = set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MDA)).union(set(MBR)).union(set(SMcols)).union(set(RM)).\
union(set(XGBestCols)).union(set(SBS))
print("Extra features select by RFE:", set(FRFE).difference(set(pv_cols).union(set(MDI)).union(set(MDA)).union(set(MBR)).union(set(RM)).\
union(set(SMcols)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by pv_cols:", set(pv_cols).difference(set(FRFE).union(set(MDI)).union(set(MDA)).union(set(MBR)).union(set(SMcols)).\
union(set(RM)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by Statistical Methods:", set(SMcols).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).\
union(set(MDA)).union(set(MBR)).union(set(RM)).\
union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by MDI:", set(MDI).difference(set(pv_cols).union(set(FRFE)).union(set(MDA)).union(set(MBR)).\
union(set(SMcols)).union(set(RM)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by MDA:", set(MDA).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MBR)).\
union(set(SMcols)).union(set(RM)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by MBR:", set(MBR).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MDA)).\
union(set(SMcols)).union(set(RM)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by RM:", set(RM).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MDA)).\
union(set(SMcols)).union(set(MBR)).union(set(XGBestCols)).union(set(SBS))), '\n')
print("Extra features select by XGBestCols:", set(XGBestCols).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MDA)).\
union(set(SMcols)).union(set(MBR)).union(set(RM)).union(set(SBS))), '\n')
print("Extra features select by SBS:", set(SBS).difference(set(pv_cols).union(set(FRFE)).union(set(MDI)).union(set(MDA)).\
union(set(SMcols)).union(set(MBR)).union(set(RM)).union(set(XGBestCols))), '\n')
print("Intersection features:",set(MDI).intersection(set(SMcols)).intersection(set(FRFE)).intersection(set(pv_cols)).\
intersection(set(RM)).intersection(set(MDA)).intersection(set(MBR)).\
intersection(set(XGBestCols)).intersection(set(SBS)), '\n')
print('Total number of features selected:', len(bcols))
print(bcols)
print('\n{0:2d} features removed if use the union of selections:\n{1:}'.format(len(cols.difference(bcols)), cols.difference(bcols)))
Chose The Features From The Selection Methods¶
As you can saw the methods chose some different features that,if we consider the intersection, there is nothing left, and if the union only removes eight features.As expected, we can’t made a unique strategy, the right chose depends on your proposal and the respective model that you will run.
Since, we have few features, by the reason of don’t consider all results of hot encode of surnames, we can try some models with different sets and check the influence in the results, like we did on the methods that selecting based on accuracy of the model. In the other hand, we can make the feature selection as part of the pipeline of the model and select features based on the best for the respective model. This is allows different strategies, including the use of methods for sparse data and thus evaluate the surnames, or methods that apply regularization in data to submit to models that don’t have regularization terms.
For the submission, I already run multiple times and made choices to submit. Here for simplicity, I chose the initial result with only drop collinearity and multicollinearity, and make the selection into the pipelines, but we need first check what we can get from dimension reduction techniques.
Additional Feature Engineering: Feature transformation¶
Feature transformation (FT) refers to family of algorithms that create new features using the existing features. These new features may not have the same interpretation as the original features, but they may have more discriminatory power in a different space than the original space. This can also be used for feature reduction. FT may happen in many ways, by simple/linear combinations of original features or using non-linear functions. Some common techniques for FT are:
- Scaling or normalizing features (e.g.: StandardScaler, RobustSacaler and MinMaxScaler)
- Principle Component Analysis
- Random Projection
- Neural Networks
- SVM also transforms features internally.
- Transforming categorical features to numerical.
Polynomial Features – Create Degree 3 of some Features¶
Often it’s useful to add complexity to the model by considering nonlinear features of the input data. A simple and common method to use is polynomial features, which can get features’ high-order and interaction terms.
pf = PolynomialFeatures(degree=2, interaction_only=False, include_bias=False)
res = pf.fit_transform(data[['Pclass', 'passenger_fare']])
display(pd.DataFrame(pf.powers_, columns=['Pclass', 'passenger_fare']))
del res
# We can contact the new res with data, but we need treat the items without interactions and power,
# or if is few features it can generate and incorporate to data manually.
data['Pclass^2'] = data.Pclass**2
data['Plcass_X_p_fare'] = data.Pclass * data.passenger_fare
data['p_fare^2'] = data.passenger_fare**2
cols = cols.insert(33, 'Pclass^2')
cols = cols.insert(34, 'Plcass_X_p_fare')
cols = cols.insert(35, 'p_fare^2')
bcols.add('Pclass^2')
bcols.add('Plcass_X_p_fare')
bcols.add('p_fare^2')
scale = StandardScaler(with_std=False)
df = pd.DataFrame(scale.fit_transform(data.loc[data.Survived>=0, cols]), columns= cols)
Defining Categorical Data as Category¶
In order that the models do not make inappropriate use of features transformed into numbers and apply only calculations relevant to categorical, we have to transform their type into category type
data.Pclass = data.Pclass.astype('category')
data.genre = data.genre.astype('category')
data.distinction_in_tikect_Low = data.distinction_in_tikect_Low.astype('category')
data.distinction_in_tikect_PC = data.distinction_in_tikect_PC.astype('category')
data.distinction_in_tikect_Others = data.distinction_in_tikect_Others.astype('category')
data.Cabin_Letter_B = data.Cabin_Letter_B.astype('category')
data.Cabin_Letter_C = data.Cabin_Letter_C.astype('category')
data.Cabin_Letter_D = data.Cabin_Letter_D.astype('category')
data.Cabin_Letter_E = data.Cabin_Letter_E.astype('category')
data.Cabin_Letter_F = data.Cabin_Letter_F.astype('category')
data.Cabin_Letter_G = data.Cabin_Letter_G.astype('category')
data.Embarked_C = data.Embarked_C.astype('category')
data.Embarked_S = data.Embarked_S.astype('category')
data.Embarked_Q = data.Embarked_Q.astype('category')
data.Personal_Titles_Royalty = data.Personal_Titles_Royalty.astype('category')
data.Personal_Titles_Technical = data.Personal_Titles_Technical.astype('category')
data.Personal_Titles_Kid = data.Personal_Titles_Kid.astype('category')
data.Personal_Titles_Mrs = data.Personal_Titles_Mrs.astype('category')
data.Personal_Titles_Mr = data.Personal_Titles_Mr.astype('category')
data.Personal_Titles_Miss = data.Personal_Titles_Miss.astype('category')
data.Without_Age = data.Without_Age.astype('category')
data.distinction_in_name = data.distinction_in_name.astype('category')
data.parents = data.parents.astype('category')
data.relatives = data.relatives.astype('category')
data.sons = data.sons.astype('category')
data.companions = data.companions.astype('category')
data.surname_Alone = data.surname_Alone.astype('category')
data.surname_Baclini = data.surname_Baclini.astype('category')
data.surname_Carter = data.surname_Carter.astype('category')
data.surname_Richards = data.surname_Richards.astype('category')
data.surname_Harper = data.surname_Harper.astype('category')
data.surname_Beckwith = data.surname_Beckwith.astype('category')
data.surname_Goldenberg = data.surname_Goldenberg.astype('category')
data.surname_Moor = data.surname_Moor.astype('category')
data.surname_Chambers = data.surname_Chambers.astype('category')
data.surname_Hamalainen = data.surname_Hamalainen.astype('category')
data.surname_Dick = data.surname_Dick.astype('category')
data.surname_Taylor = data.surname_Taylor.astype('category')
data.surname_Doling = data.surname_Doling.astype('category')
data.surname_Gordon = data.surname_Gordon.astype('category')
data.surname_Beane = data.surname_Beane.astype('category')
data.surname_Hippach = data.surname_Hippach.astype('category')
data.surname_Bishop = data.surname_Bishop.astype('category')
data.surname_Mellinger = data.surname_Mellinger.astype('category')
data.surname_Yarred = data.surname_Yarred.astype('category')
Box cox transformation of highly skewed features¶
A Box Cox transformation is a way to transform non-normal dependent variables into a normal shape.
Why does this matter?
- Model bias and spurious interactions: If you are performing a regression or any statistical modeling, this asymmetrical behavior may lead to a bias in the model. If a factor has a significant effect on the average, because the variability is much larger, many factors will seem to have a stronger effect when the mean is larger. This is not due, however, to a true factor effect but rather to an increased amount of variability that affects all factor effect estimates when the mean gets larger. This will probably generate spurious interactions due to a non-constant variation, resulting in a very complex model with many spurious and unrealistic interactions.
- Normality is an important assumption for many statistical techniques: such as individuals control charts, Cp/Cpk analysis, t-tests and analysis of variance (ANOVA). A substantial departure from normality will bias your capability estimates.
One solution to this is to transform your data into normality using a Box-Cox transformation means that you are able to run a broader number of tests.
At the core of the Box Cox transformation is an exponent, lambda (λ), which varies from -5 to 5. All values of λ are considered and the optimal value for your data is selected; The ‘optimal value’ is the one which results in the best approximation of a normal distribution curve. The transformation of Y has the form:
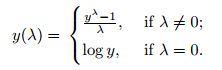
The scipy implementation proceeded with this formula, then you need before take care of negatives values if you have. A common technique for handling negative values is to add a constant value to the data prior to applying the log transform. The transformation is therefore log(Y+a) where a is the constant. Some people like to choose a so that min(Y+a) is a very small positive number (like 0.001). Others choose a so that min(Y+a) = 1. For the latter choice, you can show that a = b – min(Y), where b is either a small number or is 1.
This test only works for positive data. However, Box and Cox did propose a second formula that can be used for negative y-values, not implemented in scipy:
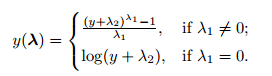
The formula are deceptively simple. Testing all possible values by hand is unnecessarily labor intensive.
Common Box-Cox Transformations
| Lambda value (λ) | Transformed data (Y’) |
|---|---|
| -3 | Y**-3 = 1/Y**3 |
| -2 | Y**-2 = 1/Y**2 |
| -1 | Y**-1 = 1/Y |
| -0.5 | Y**-0.5 = 1/(√(Y)) |
| 0 | log(Y)(*) |
| 0.5 | Y0.5 = √(Y) |
| 1 | Y**1 = Y |
| 2 | Y**2 |
| 3 | Y**3 |
(*)Note: the transformation for zero is log(0), otherwise all data would transform to Y**0 = 1.
The transformation doesn’t always work well, so make sure you check your data after the transformation with a normal probability plot or if the skew are reduced, tending to zero.
numeric_features = list(data.loc[:, cols].dtypes[data.dtypes != "category"].index)
# non_relative is skwed and have negatives values, so we need adding 6 as a shift parameter.
data['non_relatives_shift'] = data.non_relatives + 6
numeric_features.remove('non_relatives')
numeric_features.append('non_relatives_shift')
skewed_features = data[numeric_features].apply(lambda x : skew (x.dropna())).sort_values(ascending=False)
#compute skewness
skewness = pd.DataFrame({'Skew' :skewed_features})
# Get only higest skewed features
skewness = skewness[abs(skewness) > 0.7]
skewness = skewness.dropna()
print ("There are {} higest skewed numerical features to box cox transform".format(skewness.shape[0]))
l_opt = {}
#df = pd.DataFrame()
for feat in skewness.index:
#df[feat] = boxcox1p(data[feat], l_opt[feat])
#data[feat] = boxcox1p(data[feat], l_opt[feat])
data[feat], l_opt[feat] = boxcox((data[feat]+1))
#skewed_features2 = df.apply(lambda x : skew (x.dropna())).sort_values(ascending=False)
skewed_features2 = data[skewness.index].apply(lambda x : skew (x.dropna())).sort_values(ascending=False)
#compute skewness
skewness2 = pd.DataFrame({'New Skew' :skewed_features2})
display(pd.concat([skewness, skewness2], axis=1).sort_values(by=['Skew'], ascending=False))
As you can see, we were able at first to bring the numerical values closer to normal. Let’s take a look at the QQ test of these features.
def QQ_plot(data, measure):
fig = plt.figure(figsize=(12,4))
#Get the fitted parameters used by the function
(mu, sigma) = norm.fit(data)
#Kernel Density plot
fig1 = fig.add_subplot(121)
sns.distplot(data, fit=norm)
fig1.set_title(measure + ' Distribution ( mu = {:.2f} and sigma = {:.2f} )'.format(mu, sigma), loc='center')
fig1.set_xlabel(measure)
fig1.set_ylabel('Frequency')
#QQ plot
fig2 = fig.add_subplot(122)
res = probplot(data, plot=fig2)
fig2.set_title(measure + ' Probability Plot (skewness: {:.6f} and kurtosis: {:.6f} )'.\
format(data.skew(), data.kurt()), loc='center')
plt.tight_layout()
plt.show()
for feat in skewness.index:
QQ_plot(data[feat], ('Boxcox1p of {}'.format(feat)))








Compressing Data via Dimensionality Reduction¶
PCA¶
Principal component analysis (PCA) is a statistical procedure that uses an orthogonal transformation to convert a set of observations of possibly correlated variables into a set of values of linearly uncorrelated variables called principal components. If there are n observations with p variables, then the number of distinct principal components is min(n-1,p). This transformation is defined in such a way that the first principal component has the largest possible variance, and each succeeding component in turn has the highest variance possible under the constraint that it is orthogonal to the preceding components. The resulting vectors are an uncorrelated orthogonal basis set. PCA is sensitive to the relative scaling of the original variables.
Let’s see how PCA can reduce the dimensionality of our dataset with minimum of lose information:
pca_all = PCA(random_state=101, whiten=True).fit(df)
my_color=y_train.astype('category').cat.codes
# Store results of PCA in a data frame
result=pd.DataFrame(pca_all.transform(df), columns=['PCA%i' % i for i in range(df.shape[1])], index=df.index)
# Plot initialisation
fig = plt.figure(figsize=(10,10))
ax = fig.add_subplot(111, projection='3d')
ax.scatter(result['PCA0'], result['PCA1'], result['PCA2'], c=my_color, cmap="Set2_r", s=60)
# make simple, bare axis lines through space:
xAxisLine = ((min(result['PCA0']), max(result['PCA0'])), (0, 0), (0,0))
ax.plot(xAxisLine[0], xAxisLine[1], xAxisLine[2], 'r')
yAxisLine = ((0, 0), (min(result['PCA1']), max(result['PCA1'])), (0,0))
ax.plot(yAxisLine[0], yAxisLine[1], yAxisLine[2], 'r')
zAxisLine = ((0, 0), (0,0), (min(result['PCA2']), max(result['PCA2'])))
ax.plot(zAxisLine[0], zAxisLine[1], zAxisLine[2], 'r')
# label the axes
ax.set_xlabel("PC1")
ax.set_ylabel("PC2")
ax.set_zlabel("PC3")
ax.set_title("PCA on the Titanic data set")
plt.show()
X_train , X_test, y, y_test = train_test_split(df , y_train, test_size=0.3, random_state=0)
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train, y)
print('LR Training Accuracy: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train))))
y_pred = lr.predict(X_test)
print('LR Accuracy: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
print('_' * 40)
print('\nApply PCA:\n')
AccPca = pd.DataFrame(columns=['Components', 'Var_ratio', 'Train_Acc', 'Test_Acc'])
for componets in np.arange(1, df.shape[1]):
variance_ratio = sum(pca_all.explained_variance_ratio_[:componets])*100
pca = PCA(n_components=componets, random_state=101, whiten=True)
X_train_pca = pca.fit_transform(X_train)
Components = X_train_pca.shape[1]
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train_pca, y)
Training_Accuracy = accuracy_score(y, lr.predict(X_train_pca))
X_test_pca = pca.transform(X_test)
y_pred = lr.predict(X_test_pca)
Test_Accuracy = accuracy_score(y_test, y_pred)
AccPca = AccPca.append(pd.DataFrame([(Components, variance_ratio, Training_Accuracy, Test_Accuracy)],
columns=['Components', 'Var_ratio', 'Train_Acc', 'Test_Acc']))#], axis=0)
AccPca.set_index('Components', inplace=True)
display(AccPca.sort_values(by='Test_Acc', ascending=False))

In that case, although we can see some separation in planes, you can see that we lose too much information if we consider only the 3 first PCA’s, and we can get the best test accuracy from 22 components.
Linear Discriminant Analysis (LDA)¶
As a supervised dimensionality reduction technique for maximizing class separability. LDA can be used as a technique for feature extraction to increase the computational efficiency and reduce the degree of over-fitting due to the curse of dimensionality in nonregularized models.
So, the goal is to find the feature subspace that optimizes class separability.

However, even if one or more of those assumptions are slightly violated, LDA for dimensionality reduction can still work reasonably well.
Some Important Parameters:
solver : string, optional
Solver to use, possible values:
- svd: Singular value decomposition (default).
Does not compute the covariance matrix, therefore this solver is
recommended for data with a large number of features.
- eigen: Eigenvalue decomposition, can be combined with shrinkage.
shrinkage : string or float, optional
Shrinkage parameter, possible values:
- None: no shrinkage (default).
- auto: automatic shrinkage using the Ledoit-Wolf lemma.
- float between 0 and 1: fixed shrinkage parameter.
Note that shrinkage works only with 'lsqr' and 'eigen' solvers.X_train , X_test, y, y_test = train_test_split(df , y_train, test_size=0.3, random_state=0)
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train, y)
print('LR Training Accuracy: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train))))
y_pred = lr.predict(X_test)
print('LR Accuracy: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
print('_' * 40)
print('\nApply LDA:\n')
lda = LDA(store_covariance=True)
X_train_lda = lda.fit_transform(X_train, y)
#X_train_lda = pd.DataFrame(X_train_lda)
print('Number of features after LDA:',X_train_lda.shape[1])
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train_lda, y)
print('LR Training Accuracy With LDA: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train_lda))))
X_test_lda = lda.transform(X_test)
y_pred = lr.predict(X_test_lda)
print('LR Test Accuracy With LDA: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
fig = plt.figure(figsize=(20,5))
fig.add_subplot(121)
plt.scatter(X_train_lda[y==0, 0], np.zeros((len(X_train_lda[y==0, 0]),1)), color='red', alpha=0.1)
plt.scatter(X_train_lda[y==1, 0], np.zeros((len(X_train_lda[y==1, 0]),1)), color='blue', alpha=0.1)
plt.title('LDA on Training Data Set')
plt.xlabel('LDA')
fig.add_subplot(122)
plt.scatter(X_test_lda[y_test==0, 0], np.zeros((len(X_test_lda[y_test==0, 0]),1)), color='red', alpha=0.1)
plt.scatter(X_test_lda[y_test==1, 0], np.zeros((len(X_test_lda[y_test==1, 0]),1)), color='blue', alpha=0.1)
plt.title('LDA on Test Data Set')
plt.xlabel('LDA')
plt.show()

As you can saw, we have better accuracy on training after LDA, but with overfitting, sure without cross validation.
If I don’t consider the surnames below to 0.06 of correlation with survived, we can get basically the same results after LDA, with lose only 0.48% at training and 0.38% at test, but reduce the difference in 0.10%.
The LDA returns a total of components equal to the number of class minus 1, or less if you define the n_components less than the number of classes. Since our case is binary classification, we only have one column after applying the LDA.
For we can have another visualization, a small trick to having two components as a return is to fit some rows to X with a not common in their training observations, in that case with -0.1 for example, and the same number of rows with -1 to y. Let’s see it:
X_train , X_test, y, y_test = train_test_split(df , y_train, test_size=0.3, random_state=0)
X_train = X_train.append(pd.DataFrame(-np.ones((20,len(cols)))/10, columns = X_train.columns), ignore_index=True)
y = y.append(pd.Series(-np.ones((20))), ignore_index=True)
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train, y)
print('Artficial training %d observations' % X_train.Age[y==-1].count())
print('LR Training Accuracy: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train))))
y_pred = lr.predict(X_test)
print('LR Accuracy: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
print('_' * 40)
print('\nApply LDA:\n')
lda = LDA(store_covariance=True)
X_train_lda = lda.fit_transform(X_train, y)
print('Number of features after LDA:',X_train_lda.shape[1])
print('Number test observations predit as -1:', len(X_test_lda[y_test==-1, :]))
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train_lda, y)
print('LR Training Accuracy With LDA: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train_lda))))
X_test_lda = lda.transform(X_test)
y_pred = lr.predict(X_test_lda)
print('LR Test Accuracy With LDA: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
fig = plt.figure(figsize=(20,5))
fig.add_subplot(121)
plt.scatter(x=X_train_lda[y==0, 0], y=X_train_lda[y==0, 1], color='red', alpha=0.1)
plt.scatter(x=X_train_lda[y==1, 0], y=X_train_lda[y==1, 1], color='blue', alpha=0.1)
plt.title('LDA on Training Data Set')
plt.xlabel('LDA 1')
plt.ylabel('LDA 2')
fig.add_subplot(122)
plt.scatter(x=X_test_lda[y_test==0, 0], y=X_test_lda[y_test==0, 1], color='red', alpha=0.1)
plt.scatter(x=X_test_lda[y_test==1, 0], y=X_test_lda[y_test==1, 1], color='blue', alpha=0.1)
plt.title('LDA on Test Data Set')
plt.xlabel('LDA 1')
plt.ylabel('LDA 2')
plt.show()

Nonlinear dimensionality reduction via kernel principal component analysis¶
Many machine learning algorithms make assumptions about the linear separability of the input data. If we are dealing with nonlinear problems, which is more common in real cases, linear transformation techniques for dimensionality reduction like PCA and LDA, may not be the best choice. Using kernel PCA to transform nonlinear data onto a new, lower-dimensional subspace that is suitable for linear classifiers.
In what way, with kernel PCA we perform a nonlinear mapping that transforms the data onto a higher-dimensional space and use standard PCA in this higher-dimensional space to project the data back onto a lower-dimensional space where the samples can be separated by a linear classifier. However, one downside of this approach is that it is computationally very expensive.
Using the kernel trick, we can compute the similarity between two high-dimension feature vectors in the original feature space. In other words, what we obtain after kernel PCA are the samples already projected onto the respective components.
The most commonly used kernels
- The polynomial kernel.
- The hyperbolic tangent (sigmoid) kernel.
- The Radial Basis Function (RBF) or Gaussian kernel.
Scikit-learn implements a kernel PCA class and also implements manifold, a class with advanced techniques for nonlinear dimensionality reduction.
Some important parameters:
-
n_components : int, default=None. Number of components. If None, all non-zero components are kept.
-
eigen_solver : string [‘auto’|’dense’|’arpack’], default=’auto'</p>
Select eigensolver to use. If n_components is much less than the number of training samples, arpack may be more efficient than the dense eigensolver. -
kernel : “linear” | “poly” | “rbf” | “sigmoid” | “cosine” | “precomputed”. Kernel. Default=”linear”.
-
gamma : float, default=1/n_features. Kernel coefficient for rbf, poly and sigmoid kernels. Ignored by other kernels.
-
degree : int, default=3. Degree for poly kernels. Ignored by other kernels.
-
coef0 : float, default=1. Independent term in poly and sigmoid kernels. Ignored by other kernels.
Let’s start and see if kernel PCA can help with our data:
n_components = 3
kernel = 'linear'
degree = 3
gamma = 1/df.shape[0]
kpca = KernelPCA(n_components = n_components, degree = degree, random_state = 101, #gamma = gamma,
kernel = kernel, eigen_solver='arpack')
X_kpca = kpca.fit_transform(df)
# Plot first two KPCA components
fig = plt.figure(figsize=(20,6))
ax = fig.add_subplot(121)
plt.scatter(x = X_kpca[y_train==0, 0], y = X_kpca[y_train==0, 1], color='red', marker='^', alpha=0.5)
plt.scatter(x = X_kpca[y_train==1, 0], y = X_kpca[y_train==1, 1], color='blue', marker='o', alpha=0.5)
ax.set_xlabel("KPCA_0")
ax.set_ylabel("KPCA_1")
ax.set_title("Plot of first 2 KPCA Components on the Titanic data set")
my_color=y_train.astype('category').cat.codes
# Store results of PCA in a data frame
result=pd.DataFrame(X_kpca, columns=['KPCA%i' % i for i in range(n_components)], index=df.index)
# Plot initialisation
ax = fig.add_subplot(122, projection='3d')
ax.scatter(result['KPCA0'], result['KPCA1'], result['KPCA2'], c=my_color, cmap="Set2_r", s=60)
# make simple, bare axis lines through space:
xAxisLine = ((min(result['KPCA0']), max(result['KPCA0'])), (0, 0), (0,0))
ax.plot(xAxisLine[0], xAxisLine[1], xAxisLine[2], 'r')
yAxisLine = ((0, 0), (min(result['KPCA1']), max(result['KPCA1'])), (0,0))
ax.plot(yAxisLine[0], yAxisLine[1], yAxisLine[2], 'r')
zAxisLine = ((0, 0), (0,0), (min(result['KPCA2']), max(result['KPCA2'])))
ax.plot(zAxisLine[0], zAxisLine[1], zAxisLine[2], 'r')
# label the axes
ax.set_xlabel("KPCA_0")
ax.set_ylabel("KPCA_1")
ax.set_zlabel("KPCA_2")
ax.set_title("KPCA of 3 Components on the Titanic data set")
plt.tight_layout(); plt.show()
X_train , X_test, y, y_test = train_test_split(df , y_train, test_size=0.3, random_state=0)
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train, y)
print('\nLogistic Regression over data without transformation:\n' + '_' * 53 + '\n')
print('LR Training Accuracy: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train))))
y_pred = lr.predict(X_test)
print('LR Test Accuracy: {:2.2%}'.format(accuracy_score(y_test, y_pred)))
print('\nApply KPCA:\n' + '_' * 53)
kpca = KernelPCA(kernel = kernel, random_state = 101, degree = degree, eigen_solver='arpack', n_components = 23)
X_train_kpca = kpca.fit_transform(X_train)
print('Number of features after KPCA:', X_train_kpca.shape[1])
lr = LogisticRegression(class_weight='balanced', random_state=101)
lr = lr.fit(X_train_kpca, y)
print('LR Training Accuracy: {:2.2%}'.format(accuracy_score(y, lr.predict(X_train_kpca))))
X_test_kpca = kpca.transform(X_test)
y_pred = lr.predict(X_test_kpca)
print('LR Test Accuracy: {:2.2%}'.format(accuracy_score(y_test, y_pred)))

Although the algorithm is admittedly exhaustive, as we have few data it runs very well, even using a single core.
So, instead of proceeding with a hyper parameterization via grid search, I chose to run manually with some variations to see the graphs and results on accuracy. I leave the best result I got, but if you want you can proceed with play it and check for yourself.
My conclusions are:
- The liner solver not exceeding PCA and we don’t see a great difference in accuracy, if we define the number of features to 23, and get the same with 45.
- The poly solver degenerate our accuracy.
- With rbf solver we have overfitting.
- With sigmoid or cosine the accuracy is the worst.
So applying nonlinear transformations to all of these data may not be the best, and it’s important checked it against your model’s performance. Also, as you may notice these transformations are subject to hyper parameterization, then, you should not ignore this if your case is computationally costs
Feature Selection into the Pipeline¶
Since we have a very different selection of features selection methods, from the results it may be interesting keeping only the removal of collinear, multicollinear and most of one-hot encode results from surnames, and apply PCA around 22 or LDA to linear models, and we can still improve the results through hyper parameterization and cross-validation.
class select_fetaures(object): # BaseEstimator, TransformerMixin,
def __init__(self, select_cols):
self.select_cols_ = select_cols
def fit(self, X, Y ):
print('Recive {0:2d} features...'.format(X.shape[1]))
return self
def transform(self, X):
print('Select {0:2d} features'.format(X.loc[:, self.select_cols_].shape[1]))
return X.loc[:, self.select_cols_]
def fit_transform(self, X, Y):
self.fit(X, Y)
df = self.transform(X)
return df
#X.loc[:, self.select_cols_]
def __getitem__(self, x):
return self.X[x], self.Y[x]
Test_ID = data.PassengerId[data.Survived<0]
y_train = data.Survived[data.Survived>=0]
train = data.loc[data.Survived>=0, list(cols)]
test = data.loc[data.Survived<0, list(cols)]
Modeling – Hyper Parametrization¶
First, we start to looking at different approaches to implement classifiers models, and use hyper parametrization, cross validation and compare the results between different errors measures.
The standard error of the coefficient (std err) indicates the precision of the coefficient estimates. Smaller values represent more reliable estimates.
When you run two models to check the effects of multicollinearity, ever compare the Summary of Model statistics between the two models and you’ll notice that Pseudo R-squ. and the others are all identical, if the effects is None or minimal. In that case multicollinearity doesn’t affect how well the model fits. In fact, if you want to use the model to make predictions, both models produce identical results for fitted values and prediction intervals!
Simplify Get Results¶
Let’s build a function to standardize the capture and exposure of the results of our models.
def get_results(model, name, results=None, data=train, reasume=False):
modelo = model.fit(data, y_train)
print('Mean Best Accuracy: {:2.2%}'.format(gs.best_score_))
print(gs.best_params_,'\n')
best = gs.best_estimator_
param_grid = best
y_pred = model.predict(data)
meu.display_model_performance_metrics(true_labels=y_train, predicted_labels=y_pred)
print('\n\n ROC AUC Score: {:2.2%}'.format(roc_auc_score(y_true=y_train, y_score=y_pred)))
if hasattr(param_grid, 'predict_proba'):
prob = model.predict_proba(data)
score_roc = prob[:, prob.shape[1]-1]
prob = True
elif hasattr(param_grid, 'decision_function'):
score_roc = model.decision_function(data)
prob = False
else:
raise AttributeError("Estimator doesn't have a probability or confidence scoring system!")
fpr, tpr, thresholds = roc_curve(y_true=y_train, y_score=score_roc)
roc_auc = auc(fpr, tpr)
plt.title('Receiver Operating Characteristic (ROC) Curve')
plt.plot(fpr, tpr, 'b', label='AUC = {:2.2%}'.format(roc_auc))
plt.legend(loc='lower right')
plt.ylabel('True Positive Rate')
plt.xlabel('False Positive Rate')
plt.plot([0, 1], [0, 1], 'k--')
plt.show()
r1 = pd.DataFrame([(prob, gs.best_score_, np.round(accuracy_score(y_train, y_pred), 4),
roc_auc_score(y_true=y_train, y_score=y_pred), roc_auc)], index = [name],
columns = ['Prob', 'CV Accuracy', 'Acc All', 'ROC AUC Score', 'ROC Area'])
if reasume:
results = r1
elif (name in results.index):
results.loc[[name], :] = r1
else:
results = results.append(r1)
return results, modelo
Logistic Regression¶
This class implements regularized logistic regression using the ‘liblinear’ library, ‘newton-cg’, ‘sag’ and ‘lbfgs’ solvers. It can handle both dense and sparse input.
Additional Parameters
-
class_weight : dict or ‘balanced’, default: None
The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data asn_samples / (n_classes * np.bincount(y)).For how class_weight works: It penalizes mistakes in samples of class[i] with class_weight[i] instead of 1. So higher class-weight means you want to put more emphasis on a class. For example, our class 0 is 1.24 times more frequent than class 1. So you should increase the class_weight of class 1 relative to class 0, say {1: 0.6, 0: 0.4}. If the class_weight doesn’t sum to 1, it will basically change the regularization parameter.
“balanced” basically means replicating the smaller class until you have as many samples as in the larger one, but in an implicit way.
- warm_start : bool, default: False. Useless for liblinear solver.
'clf__multi_class' : ['ovr', 'multinomial']for'clf__solver': ['newton-cg', 'sag', 'lbfgs']
Attributes:
- coef_ : array, shape (1, n_features) or (n_classes, n_features)
- intercept_ : array, shape (1,) or (n_classes,)
- niter : array, shape (n_classes,) or (1, )
See also:
- SGDClassifier : incrementally trained logistic regression (when given the parameter
loss="log"). -
sklearn.svm.LinearSVC : learns SVM models using the same algorithm.
See the best results below, wheres get with PCA 21 but take more time then LDA.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', LogisticRegression(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
C = [0.008, 0.007, 0.009, 0.01]#, 0.1, 1.0, 10.0, 100.0, 1000.0]
tol = [0.001, 0.003, 0.002, 0.005] # [1e-06, 5e-07, 1e-05, 1e-04, 1e-03, 1e-02, 1e-01]
param_grid =\
[{'clf__C': C
,'clf__solver': ['liblinear', 'saga']
,'clf__penalty': ['l1', 'l2']
,'clf__tol' : tol
,'clf__class_weight': ['balanced']
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
},
{'clf__C': C
,'clf__max_iter': [3, 9, 2, 7, 4]
,'clf__solver': ['newton-cg', 'sag', 'lbfgs']
,'clf__penalty': ['l2']
,'clf__tol' : tol
,'clf__class_weight': ['balanced']
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(shadow))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, lr = get_results(main_pip, 'LogisticRegression', reasume=True)

SGDClassifier¶
This estimator implements regularized linear models with stochastic gradient descent (SGD) learning: the gradient of the loss is estimated each sample at a time and the model is updated along the way with a decreasing strength schedule (aka learning rate). SGD allows minibatch (online/out-of-core) learning, see the partial_fit method. For best results using the default learning rate schedule, the data should have zero mean and unit variance.
This implementation works with data represented as dense or sparse arrays of floating point values for the features. The model it fits can be controlled with the loss parameter; by default, it fits a linear support vector machine (SVM).
The regularizer is a penalty added to the loss function that shrinks model parameters towards the zero vector using either the squared euclidean norm L2 or the absolute norm L1 or a combination of both (Elastic Net). If the parameter update crosses the 0.0 value because of the regularizer, the update is truncated to 0.0 to allow for learning sparse models and achieve on-line feature selection.
Parameters:
loss:
- Classifier: hinge, log, modified_huber, squared_hinge, perceptron
- Defaults to ‘hinge’, which gives a linear SVM.
- The ‘log’ loss gives logistic regression, a probabilistic classifier.
- ‘modified_huber’ is another smooth loss that brings tolerance to outliers as well as probability estimates.
- ‘squared_hinge’ is like hinge but is quadratically penalized.
- ‘perceptron’ is the linear loss used by the perceptron algorithm.
- regression: squared_loss, huber, epsilon_insensitive, squared_epsilon_insensitive
penalty: The penalty (aka regularization term) to be used. Defaults to ‘l2’ which is the standard regularizer for linear SVM models. ‘l1’ and ‘elasticnet’ might bring sparsity to the model (feature selection) not achievable with ‘l2’.
alpha: Constant that multiplies the regularization term. Defaults to 0.0001 Also used to compute learning_rate when set to ‘optimal’.
l1_ratio: The Elastic Net mixing parameter, with 0 <= l1_ratio <= 1. l1_ratio=0 corresponds to L2 penalty, l1_ratio=1 to L1. Defaults to 0.15.
tol: The stopping criterion. If it is not None, the iterations will stop when (loss > previous_loss – tol).Defaults to 1e-3 from 0.21.
learning_rate:
- ‘constant’: eta = eta0
- ‘optimal’: eta = 1.0 / (alpha * (t + t0)) [default]
- ‘invscaling’: eta = eta0 / pow(t, power_t)
where t0 is chosen by a heuristic proposed by Leon Bottou.
eta0: The initial learning rate for the constant or invscaling schedules. The default value is 0.0 as eta0 is not used by the default schedule ‘optimal’.
power_t: The exponent for inverse scaling learning rate [default 0.5].
class_weight: dict, {class_label: weight} or “balanced” or None, optional
- The “balanced” mode uses the values of y to automatically adjust weights inversely proportional to class frequencies in the input data as n_samples / (n_classes * np.bincount(y))
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', SGDClassifier(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [30, 22, 21, 50]
whiten = [True, False]
alpha = [4e-03, 5e-03, 6e-03, 1e-03]
tol = [1e-08, 1e-07, 5e-09]
param_grid =\
[{'clf__loss': ['hinge', 'log', 'modified_huber', 'squared_hinge', 'perceptron']
,'clf__tol': tol
,'clf__alpha': alpha
,'clf__penalty': ['l2', 'l1']
,'clf__class_weight' : ['balanced']
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
},
{'clf__loss': ['hinge', 'log', 'modified_huber', 'squared_hinge', 'perceptron']
,'clf__tol': tol
,'clf__alpha': alpha
,'clf__penalty': ['elasticnet']
,'clf__l1_ratio' : [0.3, 0.5, 0.1]
,'clf__class_weight' : ['balanced']
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(FRFE))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, svm = get_results(main_pip, 'SGDClassifier', results)

Linear Support Vector Classification¶
Similar to SVC with parameter kernel=’linear’, but implemented in terms of liblinear rather than libsvm, so it has more flexibility in the choice of penalties and loss functions and should scale better to large numbers of samples.
This class supports both dense and sparse input and the multiclass support is handled according to a one-vs-the-rest scheme.
The combination of penalty=’l1′ and loss=’hinge’ is not supported, and penalty=’l2′ and loss=’hinge’ needs dual=True.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', LinearSVC(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
C = [0.5, 0.3, 0.05, 0.1] #, 1.0, 10.0, 100.0, 1000.0]
tol = [1e-06, 3e-06, 5e-07]
max_iter = [9, 15, 7]
param_grid =\
[{'clf__loss': ['hinge']
,'clf__tol': tol
,'clf__C': C
,'clf__penalty': ['l2']
,'clf__class_weight' : ['balanced']
,'clf__max_iter' : max_iter
,'clf__dual' : [True]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}
,{'clf__loss': ['squared_hinge']
,'clf__tol': tol
,'clf__C': C
,'clf__penalty': ['l2', 'l1']
,'clf__class_weight' : ['balanced']
,'clf__max_iter' : max_iter
,'clf__dual' : [False]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(FRFE))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, lsvc = get_results(main_pip, 'LinearSVC', results)
Gaussian Process Classifier (GPC)¶
Internally, the Laplace approximation is used for approximating the non-Gaussian posterior by a Gaussian.
Currently, the implementation is restricted to using the logistic link function. For multi-class classification, several binary one-versus rest classifiers are fitted. Note that this class thus does not implement a true multi-class Laplace approximation.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', GaussianProcessClassifier(1.0 * RBF(1.0), random_state=101))
])
# n_restarts_optimizer=5
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
max_iter_predict = [5, 10, 15, 20]
param_grid =\
[{'clf__max_iter_predict': max_iter_predict
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(bcols))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, gpc = get_results(main_pip, 'GaussianProcessClassifier', results)

Random Forest Classifier¶
A random forest is a meta estimator that fits a number of decision tree classifiers on various sub-samples of the dataset and use averaging to improve the predictive accuracy and control over-fitting. The sub-sample size is always the same as the original input sample size but the samples are drawn with replacement if bootstrap=True (default).
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', RandomForestClassifier(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
param_grid =\
[{'clf__n_estimators' : [500, 3000]
,'clf__criterion': ['gini', 'entropy']
,'clf__min_samples_split': [4, 3, 5]
,'clf__min_impurity_split': [0.05, 0.03, 0.07]
#,'clf__max_depth': [5, 10]
#,'clf__min_impurity_decrease': [0.0003]
#,'clf__min_samples_leaf': [1,2,3,4]
,'clf__class_weight': ['balanced']
#,'clf__bootstrap': [True, False]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
sele = bcols
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(sele))),
('scl', StandardScaler()),
('gs', gs)
])
results, rfc = get_results(main_pip, 'RandomForestClassifier', results)

AdaBoost classifier¶
Is a meta-estimator that begins by fitting a classifier on the original dataset and then fits additional copies of the classifier on the same dataset but where the weights of incorrectly classified instances are adjusted such that subsequent classifiers focus more on difficult cases.
This class implements the algorithm known as AdaBoost-SAMME.
Parameters:
-
n_estimators: The maximum number of estimators at which boosting is terminated. In case of perfect fit, the learning procedure is stopped early.
-
learning_rate: Learning rate shrinks the contribution of each classifier by learning_rate. There is a trade-off between learning_rate and n_estimators.
-
algorithm: {‘SAMME’, ‘SAMME.R’}. If ‘SAMME.R’ then use the SAMME.R real boosting algorithm. base_estimator must support calculation of class probabilities. If ‘SAMME’ then use the SAMME discrete boosting algorithm. The SAMME.R algorithm typically converges faster than SAMME, achieving a lower test error with fewer boosting iterations.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', AdaBoostClassifier(random_state=101))])
# , max_iter_predict=500, n_restarts_optimizer=5
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
param_grid =\
[{'clf__learning_rate': [3e-03, 15e-02, 5e-02]
,'clf__n_estimators': [300, 350, 400, 500] # np.arange(96,115)
,'clf__algorithm' : ['SAMME', 'SAMME.R']
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(FRFE))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, AdaB = get_results(main_pip, 'AdaBoostClassifier', results)

clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', KNeighborsClassifier())])
#max_iter_predict=500, n_restarts_optimizer=5
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
param_grid =\
[{'clf__n_neighbors': [3, 7, 8, 9] #
,'clf__weights': ['uniform', 'distance']
,'clf__algorithm' : ['ball_tree', 'kd_tree'] # ['auto', 'ball_tree', 'kd_tree', 'brute']
,'clf__leaf_size': [12, 15, 16, 20]
,'clf__p': [1, 2]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(FRFE))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, KNNC = get_results(main_pip, 'KNeighborsClassifier', results)

Multi-layer Perceptron classifier¶
This model optimizes the log-loss function using LBFGS or stochastic gradient descent.
MLPClassifier trains iteratively since at each time step the partial derivatives of the loss function with respect to the model parameters are computed to update the parameters.
It can also have a regularization term added to the loss function that shrinks model parameters to prevent overfitting.
This implementation works with data represented as dense numpy arrays or sparse scipy arrays of floating point values.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', MLPClassifier(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [25, 22, 31, 54]
whiten = [True, False]
param_grid =\
[{#'clf__activation': ['identity', 'logistic', 'tanh', 'relu'],
'clf__solver': ['adam'] # , 'lbfgs', 'sgd'
,'clf__tol': [5e-04] #, 3e-04, 7e-04]
#,'clf__max_iter': [200, 1000]
,'clf__alpha': [1e-06] #, 1e-07, 1e-08]
,'clf__learning_rate_init': [3e-04]
,'clf__hidden_layer_sizes': [(512, 256, 128, 64, )]#, (1024, 512, 256, 128, 64, )]
,'clf__batch_size': [64]
,'clf__epsilon': [1e-08]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
},
{'clf__solver': ['sgd']
,'clf__tol': [5e-04]
,'clf__learning_rate_init': [3e-04]
,'clf__learning_rate': ['constant', 'adaptive']
,'clf__alpha': [1e-06] #, 1e-07, 1e-08] #, 1e-03, 1e-02, 1e-01]
,'clf__hidden_layer_sizes': [(512, 256, 128, 64, )]#, (1024, 512, 256, 128, 64, )]
,'clf__batch_size': [64]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
},
{'clf__solver': ['sgd']
,'clf__tol': [5e-04]
,'clf__learning_rate_init': [3e-04]
,'clf__learning_rate': ['invscaling']
,'clf__power_t' : [ 0.25, 0.5]
,'clf__alpha': [1e-06]
,'clf__hidden_layer_sizes': [(256, 128, 64, 32, )]
,'clf__batch_size': [64]
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(cols))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, mlpc = get_results(main_pip, 'MLPClassifier', results)

Gradient Boosting for Classification¶
GB builds an additive model in a forward stage-wise fashion; it allows for the optimization of arbitrary differentiable loss functions. In each stage nclasses regression trees are fit on the negative gradient of the binomial or multinomial deviance loss function. Binary classification is a special case where only a single regression tree is induced.
- loss: loss function to be optimized. ‘deviance’ refers to deviance (= logistic regression) for classification with probabilistic outputs. For loss ‘exponential’ gradient boosting recovers the AdaBoost algorithm.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', GradientBoostingClassifier(random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
#cv=None, dual=False, scoring=None, refit=True, multi_class='ovr'
n_components= [25, 22, 31, 54]
whiten = [True, False]
learning_rate = [1e-02] #, 5e-03, 2e-02]
n_estimators= [140, 150, 160, 145]
max_depth = [2, 3, 5]
param_grid =\
[{'clf__learning_rate': learning_rate
,'clf__max_depth': max_depth
,'clf__n_estimators' : n_estimators
#,'pca__n_components' : n_components
#,'pca__whiten' : whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=5, verbose=1, n_jobs=3)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(FRFE))),
('scl', StandardScaler()),
('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, GBC = get_results(main_pip, 'GradientBoostingClassifier', results)

XGBoost (eXtreme Gradient Boosting)¶
XGBoost is an advanced implementation of gradient boosting algorithm. It’s a highly sophisticated algorithm, powerful enough to deal with all sorts of irregularities of data.
- Standard GBM implementation has no regularization like XGBoost, therefore it also helps to reduce overfitting.
- XGBoost implements parallel processing to making a tree using all cores and is blazingly faster as compared to GBM.
- XGBoost also supports implementation on Hadoop.
- High flexibility, it allow users to define custom optimization objectives and evaluation criteria.
- XGBoost has an in-built routine to handle missing values.
- It make splits up to the max_depth specified and then start pruning the tree backwards and remove splits beyond which there is no positive gain.
- Sometimes a split of negative loss say -2 may be followed by a split of positive loss +10. GBM would stop as it encounters -2. But XGBoost will go deeper and it will see a combined effect of +8 of the split and keep both.
- XGBoost allows user to run a cross-validation at each iteration of the boosting process and thus it is easy to get the exact optimum number of boosting iterations in a single run. You don’t need use grid search.
- User can start training an XGBoost model from its last iteration of previous run.
The overall parameters have been divided into 3 categories by XGBoost authors, let’s see the most importants:
- General Parameters: Guide the overall functioning:
- booster: default is gbtree fom [‘gbtree’, ‘gblinear’]
- Booster Parameters: Guide the individual booster (tree/regression) at each step:
- learning_rate (eta): default is 0.3. Makes the model more robust by shrinking the weights on each step. Typical final values to be used: 0.01-0.2
- min_child_weight: default is 1. Defines the minimum sum of weights of all observations required in a child. Used to control over-fitting. Higher values prevent a over-fitting, but too high values can lead to under-fitting hence, it should be tuned using CV.
- max_depth: default is 6. The maximum depth of a tree used to control over-fitting and should be tuned using CV. Typical values: 3-10
- max_leaf_nodes: The maximum number of terminal nodes or leaves in a tree. Can be defined in place of max_depth. Since binary trees are created, a depth of ‘n’ would produce a maximum of 2^n leaves. If this is defined, GBM will ignore max_depth.
- gamma: default is 0. A node is split only when the resulting split gives a positive reduction in the loss function. Gamma specifies the minimum loss reduction required to make a split. Makes the algorithm conservative. The values can vary depending on the loss function and should be tuned.
- max_delta_step: default is 0. In maximum delta step we allow each tree’s weight estimation to be. If the value is set to 0, it means there is no constraint. If it is set to a positive value, it can help making the update step more conservative. Usually this parameter is not needed, but it might help in logistic regression when class is extremely imbalanced.
- subsample: default is 1. Denotes the fraction of observations to be randomly samples for each tree. Lower values make the algorithm more conservative and prevents overfitting but too small values might lead to under-fitting. Typical values: 0.5-1
- colsample_bytree: default is 1. Denotes the fraction of columns to be randomly samples for each tree. Typical values: 0.5-1
- colsample_bylevel: default is 1. Denotes the subsample ratio of columns for each split, in each level.
- reg_lambda (lambda): default is 1. L2 regularization term on weights, analogous to Ridge regression, it should be explored to reduce overfitting.
- reg_alpha (alpha): default is 0. L1 regularization term on weight, analogous to Lasso regression, Can be used in case of very high dimensionality so that the algorithm runs faster when implemented.
- scale_pos_weight: default is 1. A value greater than 0 should be used in case of high class imbalance as it helps in faster convergence. To balance use
sum(negative cases)/sum(positive cases)and Use AUC for evaluation.
- Learning Task Parameters: These parameters are used to define the optimization objective the metric to be calculated at each step:
- objective: default is reg:linear and binary:logistic for XGBClassifier. This defines the loss function to be minimized. Mostly used values are:
- binary:logistic –logistic regression for binary classification, returns predicted probability (not class)
- multi:softmax –multiclass classification using the softmax objective, returns predicted class (not probabilities). You also need to set an additional num_class (number of classes) parameter defining the number of unique classes
- multi:softprob –same as softmax, but returns predicted probability of each data point belonging to each class.
- eval_metric: The default values are rmse for regression and error for classification. The metric to be used for validation data. Typical values are:
- rmse – root mean square error
- mae – mean absolute error
- logloss – negative log-likelihood
- error – Binary classification error rate (0.5 threshold)
- merror – Multiclass classification error rate
- mlogloss – Multiclass logloss
- auc: Area under the curve
- seed: The random number seed. Can be used for generating reproducible results and also for parameter tuning.
- objective: default is reg:linear and binary:logistic for XGBClassifier. This defines the loss function to be minimized. Mostly used values are:
Before proceeding further, since cgb don’t accept categorical let’s change it to boolean or integer.
def categorical_change_back(df):
categorical_features = list(df.dtypes[df.dtypes == "category"].index)
for feat in categorical_features:
if len(df[feat].unique())==2:
df[feat] = df[feat].astype(bool)
else:
df[feat] = df[feat].astype(int)
return df
trainXGB = data.loc[data.Survived>=0, cols].copy()
trainXGB = categorical_change_back(trainXGB)
testXGB = data.loc[data.Survived<0, cols].copy()
testXGB = categorical_change_back(testXGB)
General Approach for Parameter Tuning:
- Choose a relatively high learning rate. Generally a learning rate of 0.1 works but somewhere between 0.05 to 0.3 should work for different problems. Determine the optimum number of trees for this learning rate. XGBoost has a very useful function called as ‘cv’ which performs cross-validation at each boosting iteration and thus returns the optimum number of trees required.
- Tune tree-specific parameters ( max_depth, min_child_weight, gamma, subsample, colsample_bytree) for decided learning rate and number of trees. Note that we can choose different parameters to define a tree and I’ll take up an example here.
- Tune regularization parameters (lambda, alpha) for xgboost which can help reduce model complexity and enhance performance.
- Lower the learning rate and decide the optimal parameters .
- max_depth: This should be between 3-10. 4-6 can be good starting points.
- min_child_weight: Define a smaller value if your data set is a highly imbalanced class problem and leaf nodes can have smaller size groups.
- gamma: apply L1 regularization, a smaller value like 0.1-0.2 can also be chosen for starting.
- subsample, colsample_bytree: 0.8 is a commonly used used start value. Typical values range between 0.5-0.9.
- scale_pos_weight: use to balance, for binary class do ((len(y_train)-y_train.sum())/y_train.sum()).
- reg_lambda: apply L2 regularization to reduce overfitting. Though many people don’t use this parameters much as gamma provides a substantial way of controlling complexity. But we should always try it.
clf = Pipeline([
#('pca', PCA(random_state = 101)),
('clf', XGBClassifier(learning_rate = 0.1, n_estimators=200, max_depth=5,
min_child_weight=1, gamma=0, subsample=0.8, colsample_bytree=0.8, importance_type='gain',
objective= 'binary:logistic', n_jobs=4, scale_pos_weight=scale, seed=101, random_state=101))])
# a list of dictionaries to specify the parameters that we'd want to tune
n_components= [5, 10, 15, 19, 21] # [25, 22, 31, 54]
whiten = [True, False]
scale = ((len(y_train)-y_train.sum())/y_train.sum())
sample = np.arange(5,10)/10
param_grid = \
[{
'clf__max_depth': [3, 4],
'clf__min_child_weight': range(1,5),
'clf__gamma': np.arange(0,11)/10,
'clf__reg_alpha': np.arange(0,11)/10,
'clf__subsample' : sample,
'clf__colsample_bytree' :sample
#,'pca__n_components' : n_components
#,'pca__whiten' : [True] # whiten
}]
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=3, verbose=1, n_jobs=4)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(pv_cols))),
#('scl', StandardScaler()),
#('lda', LDA(store_covariance=True)),
('gs', gs)
])
results, xgb1 = get_results(main_pip, 'XGBClassifier', results, data = trainXGB)

You may have noticed that the number of estimators is actually a parameter that defines the maximum of interactions, whether or not your final model has this number of estimators.
In fact, the ideal is that it has a smaller number, because this means that its model actually found a local minimum. In fact, this local minimum may not be great, so making a choice by a high number when you are running a grid search may be the best.
However, you may experience performance issues, so you will be tempted to perform some low number interactions to try to find the best possible values for your other parameters and then proceed with an additional round with a high number of estimators. Although this is a valid attitude, beware of the fact that by doing this you may be discarding some value from another parameter, which would actually be used with a number of estimators to be greater than you have defined.
My recommendation is that after you have tried a bit, and have understood a little more how your model is performing in front of the data, make a run with the number of larger estimators and keep the others in some range, however small, or that it has the value found and two opposite ends.
Since you are verbose in 1, you will be able to estimate the total execution time right after some tasks have been completed, and then evaluate whether you prefer to abort and reduce the number of estimators or the range of some of the other parameters.
Once you have reached a set of parameters that satisfied you, it is interesting that you run it once again, and check if a lower learning rate and higher estimators can produce better results. Let’s do it and use our normal 5 CV to get the final model:
# a list of dictionaries to specify the parameters that we'd want to tune
scale = ((len(y_train)-y_train.sum())/y_train.sum())
param_grid = \
[{
'clf__learning_rate': [0.1, 0.09, 0.03, 0.01, 0.001],
'clf__n_estimators': [200, 3000]
}]
clf = Pipeline([
('clf', XGBClassifier(learning_rate =0.1, n_estimators=2000, max_depth=3, min_child_weight=2, gamma=0.0,
subsample=0.9, colsample_bytree=0.7, objective= 'binary:logistic', importance_type='gain',
reg_alpha = 0.9, n_jobs=4, scale_pos_weight=scale, seed=101, random_state=101))])
gs = GridSearchCV(estimator=clf, param_grid=param_grid, scoring='accuracy', cv=3, verbose=1, n_jobs=4)
main_pip = Pipeline([
('sel', select_fetaures(select_cols=list(pv_cols))),
('gs', gs)
])
results, xgbF = get_results(main_pip, 'XGBClassifier Final', results, data = trainXGB)
Finalize The Model: Stacking the Models¶
Check the best results from the models hyper parametrization¶
display(results.sort_values(by='ROC Area', ascending=False))
Validation Function¶
n_folds = 10
def cvscore(model):
kf = KFold(n_folds, shuffle=True, random_state=101).get_n_splits(train.values)
score= cross_val_score(estimator=model, X=train.values, y=y_train, scoring="accuracy", verbose=1, n_jobs=3, cv = kf)
return(score)
Make Staked Classifier¶
Create an ensemble model by staked models with mean probabilities.
models = ( xgbF, rfc, GBC, AdaB, mlpc, gpc, lr, KNNC )
trained_models = []
for model in models:
#model.fit(train, targets) models all ready fited
trained_models.append(model)
predictions = []
for i, model in enumerate(trained_models):
if i < 1:
predictions.append(model.predict_proba(testXGB)[:, 1])
else:
predictions.append(model.predict_proba(test)[:, 1])
# Preper Submission File of Probabilities Classifier
predictions_df = pd.DataFrame(predictions).T
ensemble = predictions_df.mean(axis=1).map(lambda s: 1 if s >= 0.5 else 0)
submit = pd.DataFrame()
submit['PassengerId'] = Test_ID.values
submit['Survived'] = ensemble
# ----------------------------- Create File to Submit --------------------------------
submit.to_csv('Titanic_Probabilities_submission.csv', index = False)
print('Sample of Probabilities Submit:')
display(submit.head())
Conclusion¶
As you saw from the results of the models, their accuracy from cross validation vary from 82.27% to 84.74%. In the other hand, you see a more large variance on the ROC accuracy, from 87.93% to 99.31%. Since this accuracy is taken by the probabilities, not by the results class, it may suggest to use a different sets of models to assembly.
In fact, if you submit this stacked classifier as it stands, you’ll hit the 0.78947 score, which is exactly the same score I got with just Random Forest in R on my first submission. But, if you play around little you can get best score, if you pay attention to not get into overfitting.
Finally, as you saw, this is a interesting case to training techniques, because it is not easy to obtain a high score without risk of some overfitting, since it really have some cases wheres too specific. If you try submit to the competition, you discover that you can find some models that have high score, and you use cross validation and take other actions to dealing with overfitting, but your score is worse than other with minor score that you had submitted. Don’t give up!
For next steps, you can try:
- Try other models like Tensorflow
- Try others configurations of stacked models (Voting, Mean Probabilities with other set of models)
- Not apply boxcox1p on discrete data, or apply on all numeric but before the selection features
- Create others features and make other transformations

{kind=link}
{kind=link}
Hi there! Such a good article, thanks!
Hi there! Such a wonderful write-up, thank you!
Greetings! Very useful advice in this particular article! It’s the little changes that will make the largest changes. Thanks for sharing!
I have to thank you for the efforts you’ve put in penning this site. I’m hoping to view the same high-grade blog posts by you later on as well. In truth, your creative writing abilities has inspired me to get my own, personal website now 😉
May I simply say what a relief to uncover an individual who really understands what they are discussing on the web. You actually understand how to bring an issue to light and make it important. A lot more people have to look at this and understand this side of the story. I was surprised that you aren’t more popular since you certainly have the gift.